Two-Step RAG for Metadata Filtering and Statistical LLM Evaluation
Integrating Prompt-Aware Retrieval and Bootstrap Mixed Models
Keywords:
Retrieval-Augmented Generation, Metadata Filtering, Large Language Models, NCM Classification, Information RetrievalAbstract
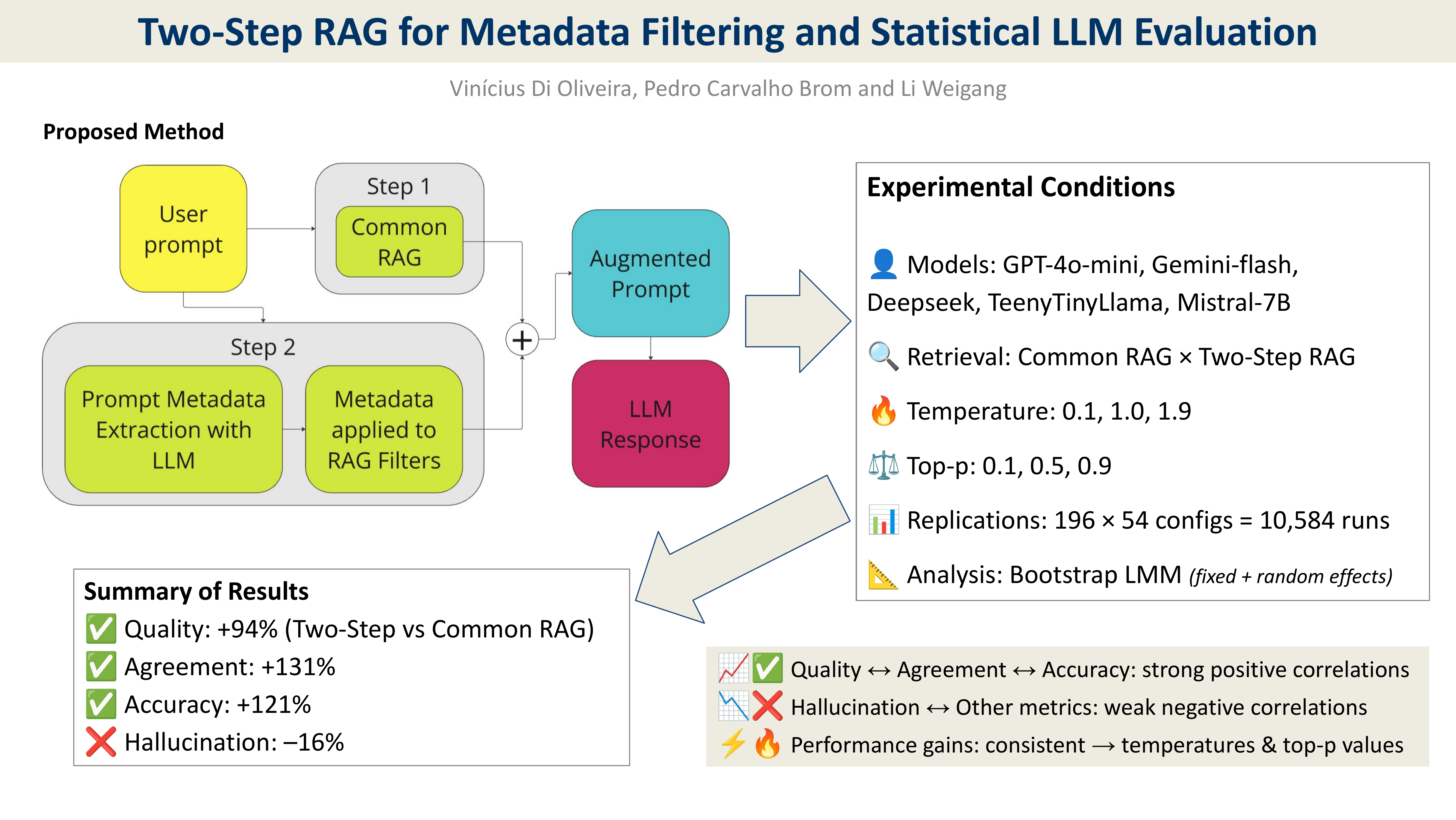
This study addresses a limitation in Retrieval-Augmented Generation (RAG) systems: poor retrieval accuracy when vague prompts or metadata are missing. We propose the Two-Step RAG method to overcome this. The first step performs a broad semantic search. The second uses an LLM to extract structured metadata to refine results through contextual filtering. This structure balances coverage and precision, proving effective in well-structured domains such as the Mercosur Common Nomenclature (NCM). The method is evaluated using a bootstrap-based multivariate linear mixed model, accounting for variability in temperature, top-p and prompt formulation. Two-Step RAG improves quality by a factor of 1.94, agreement by 2.31 and accuracy by 2.51 on average, while reducing hallucination to 0.82x compared to conventional RAG. It also shows reduced output variability in high-performing models, with coefficients of variation in quality dropping to 30–33% for gpt-4o-mini and deepseek-chat. These models achieve the best results, with accuracy gains exceeding 3x and hallucination reduced to 36–55% of the baseline. The method is robust across configurations and offers practical value for applications requiring high retrieval precision.
Downloads
References
M. Poliakov and N. Shvai, “Multi-meta-rag: Improving RAG for multi-hop queries using database filtering with LLM-extracted metadata,” in Proc. Int. Conf. on Information and Communication Technologies in Education, Research, and Industrial Applications, Springer, 2024, pp. 334–342. DOI 10.1007/978303181372625.
S. Jeong, J. Baek, S. Cho, S. J. Hwang, and J. C. Park, “Database-Augmented Query Representation for Information Retrieval,” ArXiv, 2024. DOI: 10.48550/arXiv.2406.16013.
H. Wang, T. Zhao, and J. Gao, “BlendFilter: Advancing Retrieval-Augmented Large Language Models via Query Generation Blending and Knowledge Filtering,” ArXiv, 2024. DOI: 10.48550/arXiv.2402.11129.
L. Mombaerts, T. Ding, A. Banerjee, F. Felice, J. Taws, and T. Borogovac, “Meta Knowledge for Retrieval Augmented Large Language Models,” ArXiv, 2024. DOI: 10.48550/arXiv.2408.09017.
J. Cohen, Statistical Power Analysis for the Behavioral Sciences, 2nd ed. Routledge, 1988. DOI: 10.4324/9780203771587.
P. Lewis et al., “Retrieval-augmented generation for knowledge-intensive NLP tasks,” in Advances in Neural Information Processing Systems, vol. 33, pp. 9459–9474, 2020. DOI 10.48550/arXiv.2005.11401.
H. Wang, F. Liu, Y. Dong, and D. Yu, “Entropy of eye movement during rapid automatized naming,” Frontiers in Human Neuroscience, vol. 16, 2022. DOI: 10.3389/fnhum.2022.945406.
C.-H. Liu, C.-W. Chang, J. Hung, J. J. H. Lin, P. Sung, L.-A. Lee, C.-T. Hsiao, Y.-P. Chao, E. S. Huang, and S.-L. Wang, “Brain computed tomography reading of stroke patients by resident doctors from different medical specialities: An eye-tracking study,” Journal of Clinical Neuroscience, vol. 117, pp. 173–180, 2023. DOI: 10.1016/j.jocn.2023.10.004.
J. Rystrøm, H. R. Kirk, and S. Hale, “Multilingual ≠ multicultural: Evaluating gaps between multilingual capabilities and cultural alignment in LLMs,” arXiv preprint arXiv:2502.16534, 2025. DOI 10.48550/arXiv.2502.16534.
J. P. Verma and P. Verma, “Determining Sample Size in General Linear Models,” in Statistics and Research Methods in Psychology with Excel, Springer, 2020, pp. 89–119. DOI 10.1007/97898115520457.
V. Di Oliveira, Y. Bezerra, L. Weigang, P. Brom, and V. Celestino, “SLIM-RAFT: A Novel Fine-Tuning Approach to Improve Cross-Linguistic Performance for Mercosur Common Nomenclature,” in Proc. 20th Int. Conf. on Web Information Systems and Technologies (WEBIST), SciTePress, 2024, pp. 234–241. DOI: 10.5220/0012943400003825.
V. Di Oliveira, L. Weigang, and G. P. R. Filho, “ELEVEN Data-Set: A Labeled Set of Descriptions of Goods Captured from Brazilian Electronic Invoices,” in Proc. 18th Int. Conf. on Web Information Systems and Technologies (WEBIST), SciTePress, 2022, pp. 257–264. DOI: 10.5220/0011524800003318.
Edge, Darren, et al., ”From local to global: A graph rag approach to query-focused summarization.” in arXiv preprint arXiv:2404.16130, 2024, DOI: 10.48550/arXiv.2404.16130.
O. Khattab and M. Zaharia, “ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT,” in Proc. 43rd Int. ACM SIGIR Conf. on Research and Development in Information Retrieval (SIGIR ’20), ACM, 2020, pp. 39–48. DOI: 10.1145/3397271.3401075.
N. Thakur, N. Reimers, A. Rückle ́, A. Srivastava, and I. Gurevych, “BEIR: A Heterogeneous Benchmark for Zero-Shot Evaluation of Information Retrieval Models,” in Proc. 35th Conf. on Neural Information Processing Systems (NeurIPS 2021) Datasets and Benchmarks Track, 2021. arXiv:2104.08663. DOI: 10.48550/arXiv.2104.08663
K. Lin, K. Lo, J. E. Gonzalez, and D. Klein, “Decomposing Complex Queries for Tip-of-the-Tongue Retrieval,” in Findings of the Association for Computational Linguistics: EMNLP 2023, Association for Computational Linguistics, 2023, pp. 5521–5533. DOI: 10.48550/arXiv.2305.15053