Automatic Phonetic Segmentation of the Yuhmu Language Using Mel Scale Spectral Parameters
Keywords:
Implicit Segmentation, Phoneme Analysis, Low-Resource Language, SER, Yuhmu LanguageAbstract
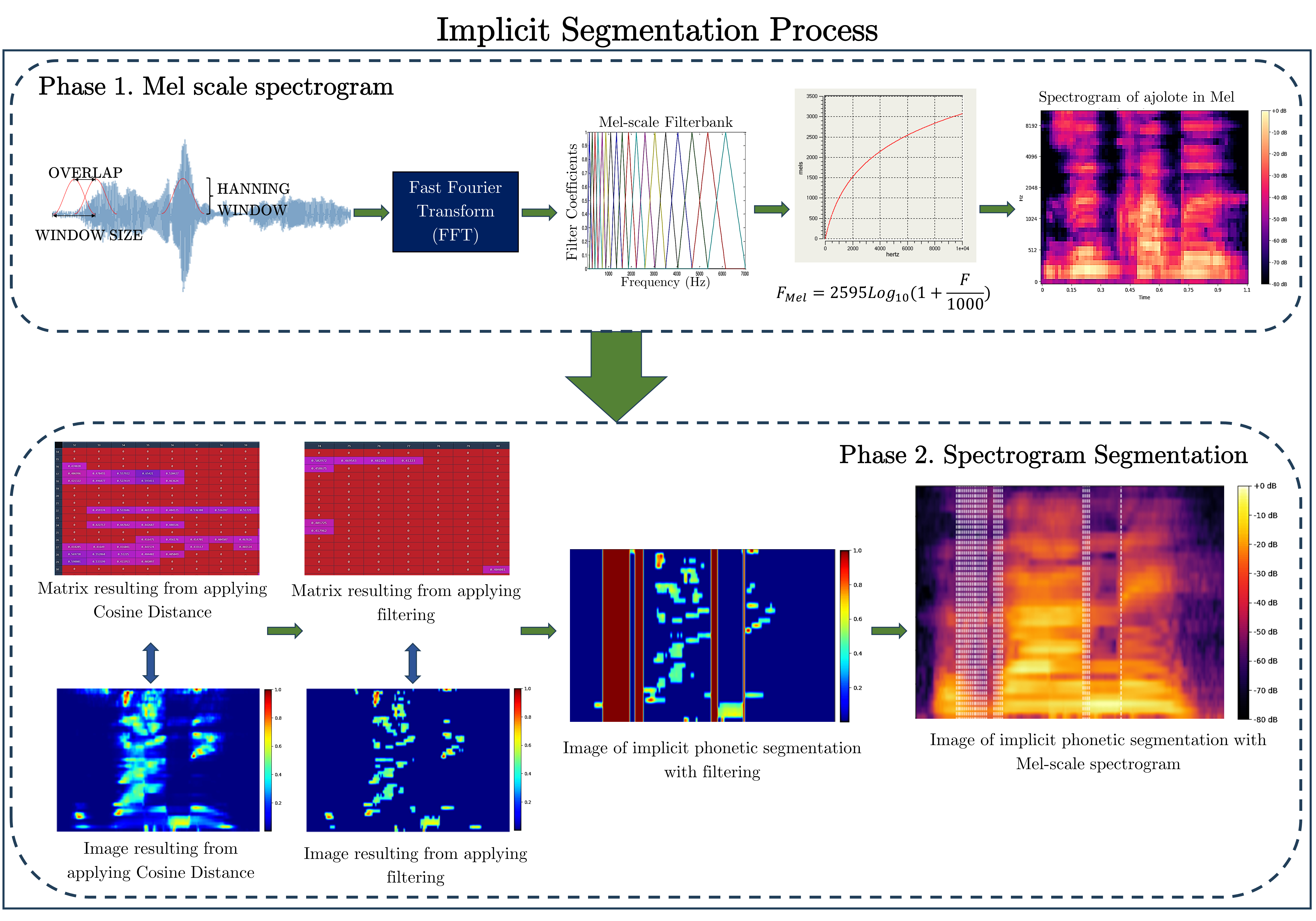
The application of digital signal processing techniques and machine learning, along with implicit segmentation, poses a challenge in the study of phonetic segmentation of indigenous languages in Mexico, given their linguistic and phonetic diversity. The analysis of Mel-scaled spectrograms offers an effective approach to identify patterns that can outline relevant information. By comparing the results with the actual number of phonemes in a word, both successes and areas for improvement can be observed. This article proposes a methodology for automatic segmental analysis of the Yuhmu language, considering parameter search in the Mel scale and implementing the cosine distance between spectrogram vectors. Additionally, relevant data within the resulting matrices are taken into account based on four key thresholds in information selection. The analysis yields a Segment Error Rate (SER) ranging from 38.79% to 41.35%, which aligns with the results reported in the literature on the subject.
Downloads
References
ChatGPT Plus
Europa Press, Los idiomas, en cifras: ¿cuántas lenguas hay en el mundo?, s.f., https://www.europapress.es/sociedad/noticia-idiomas-cifras-cuantas-lenguas-hay-mundo-20190221115202.html, Accedido: 01-octubre-2024.
F. Lasi, A study on the ability of supra-segmental and segmental aspects in English pronunciation, Ethical Lingua: Journal of Language Teaching and Literature, vol. 7, no. 2, pp. 426–437, 2020. DOI:10.30605/25409190.222
M. A. Hedderich, L. Lange, H. Adel, J. Strötgen, and D. Klakow, ”A survey on recent approaches for natural language processing in low-resource scenarios,” Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, vol. 2021, pp. 2545–2568, Jun. 2021. [Online]. Available: https://aclanthology.org/2021.naacl-main.201/. DOI: 10.18653/v1/2021.naacl-main.201
Secretaría de Cultura, México es uno de los países con mayor diversidad lingüística en el mundo, s.f., https://www.gob.mx/cultura/prensa/mexico-es-uno-de-los-paises-con-mayor-diversidad-linguistica-en-el-mundo#:∼:text=Las%20lenguas%20que%20m%C3%A1s%20se,m%C3%A1s%20de%20200%20mil%20hablantes, Accedido: 01-octubre-2024.
P. M. Rogerson-Revell, Computer-assisted pronunciation training (CAPT): Current issues and future directions, Relc Journal, vol. 52, no. 1, pp. 189–205, 2021. DOI:10.1177/0033688220977406
M. Javed, M. M. A. Baig, and S. A. Qazi, Unsupervised phonetic segmentation of classical Arabic speech using forward and inverse characteristics of the vocal tract, Arabian Journal for Science and Engineering, vol. 45, pp. 1581–1597, 2020. DOI:10.1007/s13369-019-04065-5
K. Penner, Prosodic structure in Ixtayutla Mixtec: Evidence for the foot, 2019. DOI:10.13140/RG.2.2.28786.96965
R. Turnbull, The phonetics and phonology of lexical prosody in San Jerónimo Acazulco Otomí, Journal of the International Phonetic Association, vol. 47, no. 3, pp. 251–282, 2017. DOI:10.1017/S0025100316000384
E. P. Velásquez Upegui, Entonación del español en contacto con el otomí de San Ildefonso Tultepec: Enunciados declarativos e interrogativos absolutos, Anuario de Letras. Lingüística y Filología, vol. 8, no. 2, pp. 143–168, 2020. DOI: https://doi.org/10.19130/iifl.adel.2020.24875
A. S. Sahagún, Spanish VOT Production by L1 Nahuat Speakers, PhD thesis, University of Saskatchewan, 2021.
S. Brognaux and T. Drugman, Hmm-based speech segmentation: Improvements of fully automatic approaches, IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 24, no. 1, pp. 5–15, 2015. DOI: 10.1109/TASLP.2015.2456421
M. Aissiou, A genetic model for acoustic and phonetic decoding of standard Arabic vowels in continuous speech, International Journal of Speech Technology, vol. 23, no. 2, pp. 425–434, 2020. DOI:10.1007/s10772-020-09694-y
W. Peng, Y. Gao, B. Lin, and J. Zhang, A practical way to improve automatic phonetic segmentation performance, in 2021 12th International Symposium on Chinese Spoken Language Processing (ISCSLP), pp. 1–5, 2021, IEEE. DOI:10.1109/ISCSLP49672.2021.9362107
S. Cuervo, M. Grabias, J. Chorowski, G. Ciesielski, A. Łańczucki, P. Rychlikowski, and R. Marxer, Contrastive prediction strategies for unsupervised segmentation and categorization of phonemes and words, in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 3189–3193, 2022, IEEE. DOI: 10.1109/ICASSP43922.2022.9746102
A. B. Ibrahim, Y. M. Seddiq, A. H. Meftah, M. Alghamdi, S. A. Selouani, M. A. Qamhan, Y. A. Alotaibi, and S. A. Alshebeili, Optimizing Arabic speech distinctive phonetic features and phoneme recognition using genetic algorithm, IEEE Access, vol. 8, pp. 200395–200411, 2020. DOI:10.1109/ACCESS.2020.3034762
F. Kreuk, Y. Sheena, J. Keshet, and Y. Adi, Phoneme boundary detection using learnable segmental features, in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 8089–8093, 2020. DOI: https://doi.org/10.48550/arXiv.2002.04992
I. Al-Hassani, O. Al-Dakkak, and A. Assami, Phonetic segmentation using a wavelet-based speech cepstral features and sparse representation classifier, Journal of Telecommunications and Information Technology, no. 4, pp. 12–22, 2021. DOI: https://doi.org/10.26636/jtit.2021.153321
Z. Kh. Abdul and A. K. Al-Talabani, “Mel frequency cepstral coefficient and its applications: A review,” IEEE Access, vol. 10, pp. 122136–122158, 2022. DOI: https://doi.org/10.1109/ACCESS.2022.3223444
P. Bhagath and P. K. Das, Quadrilaterals based phoneme segmentation technique for low resource spoken languages, in TENCON 2022-2022 IEEE Region 10 Conference (TENCON), pp. 1–6, 2022. DOI:10.1109/TENCON55691.2022.9977455
R. Alarcon Montero, Manual para la escritura de los sonidos del Yuhmu, INAH, 2023.
M. V. Belodedov, R. V. Fonkants, and R. R. Safin, “Development of an algorithm for optimal encoding of WAV files using genetic algorithms,” in 2023 5th International Youth Conference on Radio Electronics, Electrical and Power Engineering (REEPE), vol. 5, pp. 1–6, 2023. DOI: https://doi.org/10.1109/REEPE57272.2023.10086837
R. Liu, J. Zhang, and G. Gao, “Multi-space channel representation learning for mono-to-binaural conversion based audio deepfake detection,” Information Fusion, vol. 105, p. 102257, 2024. DOI: https://doi.org/10.1016/j.inffus.2024.102257
H. M. Fayek, “Speech Processing for Machine Learning: Filter banks, Mel-Frequency Cepstral Coefficients (MFCCs) and What’s In-Between,” 2016. [Online]. Available: https://haythamfayek.com/2016/04/21/speech-processing-for-machine-learning.html
J. Kim, Iterated grid search algorithm on unimodal criteria, Virginia Polytechnic Institute and State University, 1997.
S. Pangaonkar and A. Panat, A review of various techniques related to feature extraction and classification for speech signal analysis, in ICDSMLA 2019: Proceedings of the 1st International Conference on Data Science, Machine Learning and Applications, pp. 534–549, Springer Singapore, Singapore, 2020. DOI:10.1007/978-981-15-1420-3_57
E. Ramos-Aguilar, J. A. Olvera-López, and I. Olmos-Pineda, A general overview of language pronunciation analysis based on machine learning, Research in Computing Science, vol. 152(10), 2023.
X. Li, S. Dalmia, J. Li, M. Lee, P. Littell, J. Yao, A. Anastasopoulos, D. R. Mortensen, G. Neubig, A. W. Black, and others, Universal phone recognition with a multilingual allophone system, in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 8249–8253, 2020. DOI: https://doi.org/10.48550/arXiv.2002.11800
M. Buisson, B. McFee, S. Essid, and H. C. Crayencour, Self-supervised learning of multi-level audio representations for music segmentation, in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 2141–2152, 2024. DOI: https://doi.org/10.1109/taslp.2024.3379894