De-Occlusion Face Model based on Deep Occlusor Segmentation and Deep Inpainting Models
Keywords:
Deep learning, face reconstruction, image inpainting, occluded objects segmentationAbstract
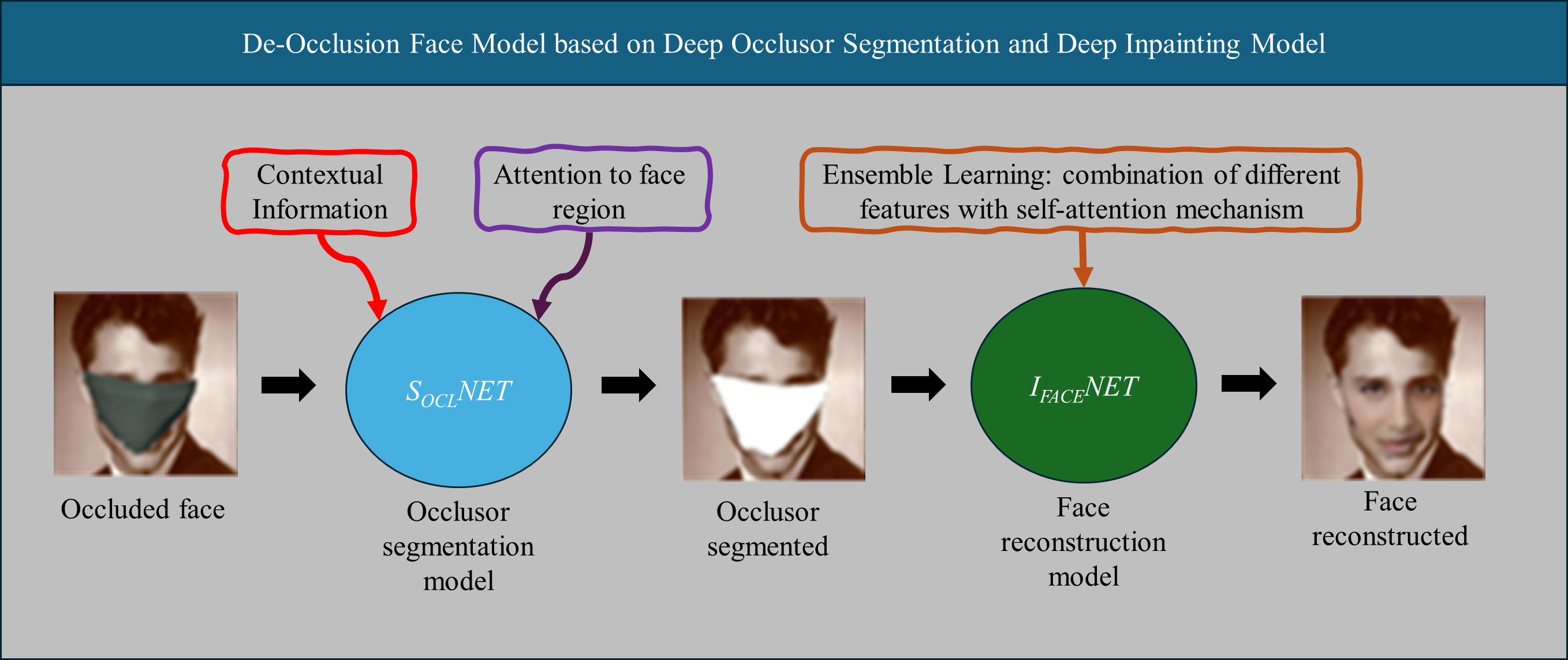
Image inpainting is a computer vision task that reconstructs missing image regions. Given its potential for various applications, it is an area of great interest. Despite advances in this field thanks to deep models such as autoencoders and generative adversarial networks, fundamental challenges persist, such as the causal interpretation of information loss and the risk of overfitting and lack of diversity in the features obtained with autoencoders. In this context, this article presents an innovative deep network model to solve occluded face inpainting. The model focuses on attributing the loss of information to the occlusion. The proposed model consists of two deep models: one for segmenting the object occluding the face, called SOCLNET, and another for reconstructing the face, IFACENET. SOCLNET is an improvement of the DeepLabv3 network by adding self-attention mechanisms. IFACENET is based on an autoencoder with an ensemble learning approach in the encoder to improve the diversity of the extracted features. SOCLNET was evaluated to demonstrate that the segmentation of occluding objects works adequately, even on out-of-distribution images. Its performance metrics were Pixel Accuracy = 0.93 and IoU = 0.788. The IFACENET model was compared against other state-of-the-art models using the Celeb-HQ database. The quantitative results of IFACENET show an average performance of SSIM = 0.95, PSNR = 26.813, and L1 = 0.261 with different mask values, being competitive with the state of the art. Additionally, qualitative results of IFACENET are shown to demonstrate the visual outcomes of face inpainting. Based on those results, it can be concluded that the proposed model effectively solves the reconstruction of occluded faces, opening new perspectives in the research of image reconstruction.
Downloads
References
H. Xiang et al., “Deep learning for image inpainting: A survey,” Pattern Recognition, vol. 134, pp. 109046, 2023. https://doi.org/10.1016/j.patcog.2022.109046
F. Qin et al., “Image inpainting based on deep learning: A review,” Displays, vol. 69, pp. 102028, 2021. https://doi.org/10.1016/j.displa.2021.102028
D. Kingma and M. Welling, “Auto-Encoding Variational Bayers,” 2013.
https://doi.org/10.48550/arXiv.1312.6114.
H. Vega et al., “Comparative study of methods to obtain the number of hidden neurons of an auto-encoder in a high-dimensionality context,” IEEE Latin America Transactions, vol. 18, no. 12, pp. 2196-2203, 2020. DOI: 10.1109/TLA.2020.9400448.
I. Goodfellow et al., “Generative Adversarial Networks,” Advances in neural information processing systems, vol. 27, 2014.
X. Yu et al., “AGG: attention-based gated convolutional GAN with prior guidance for image inpainting,” Neural Computing and Applications, pp. 1-17, 2024. https://doi.org/10.1007/s00521-024-09785-w.
D. Pathak et al., “Context Encoders: Feature Learning by Inpainting,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2536-2544, 2016. DOI: 10.1109/CVPR.2016.278.
S. Iizuka et al., “Globally and locally consistent image completion,” ACM Transactions on Graphics., vol. 36, no. 4, pp. 1–14, 2017. https://doi.org/10.1145/3072959.307365.
U. Demir and G. Unal, “Patch-Based Image Inpainting with Generative Adversarial Networks,” arXiv preprint arXiv:1803.07422, 2018.
J. Yu et al., “Generative Image Inpainting with Contextual Attention,” in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5505–5514, 2018. DOI: 10.1109/CVPR.2018.00577.
W. Quan et al., “Image Inpainting With Local and Global Refinement,” IEEE Transactions on Image Processing, vol. 31, pp. 2405–2420, 2022. DOI: 10.1109/TIP.2022.3152624.
Y. Dogan and H. Y. Keles, “Iterative facial image inpainting based on an encoder-generator architecture,” Neural Computing and Applications, vol. 34, no. 12, pp. 10001–10021, 2022. https://doi.org/10.1007/s00521-022-06987-y.
J. Yu et al., “Reference-guided face inpainting with reference attention network,” Neural Computing and Applications, vol. 34, no. 12, pp. 9717–9731, 2022. https://doi.org/10.1007/s00521-022-06961-8.
P. Shamsolmoali et al., “TransInpaint: Transformer-based Image Inpainting with Context Adaptation,” in 2023 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), pp. 849–858, 2023. DOI: 10.1109/ICCVW60793.2023.00092.
S. S. Phutke et al., “Blind Image Inpainting via Omni-dimensional Gated Attention and Wavelet Queries,” in 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 1251–1260, 2023.
X. Wang et al., “Spatially adaptive multi-scale contextual attention for image inpainting,” Multimedia Tools and Applications, vol. 81, no. 22, pp. 31831–31846, 2022. https://doi.org/10.1007/s11042-022-12489-9.
J. Jiang et al., “Parallel adaptive guidance network for image inpainting,” Applied Intelligence, vol. 53, no. 1, pp. 1162–1179, 2023. https://doi.org/10.1007/s10489-022-03387-6.
D. Cha et al., “SAC-GAN: Face Image Inpainting with Spatial-Aware Attribute Controllable GAN,” in 16th Asian Conference on Computer Vision, pp. 202–218, 2023. https://doi.org/10.1007/978-3-031-26293-7_13
Y. Zeng et al., “Aggregated Contextual Transformations for High-Resolution Image Inpainting,” IEEE Transactions on Visualization and Computer Graphics, vol. 29, no. 7, pp. 3266–3280, 2023. DOI: 10.1109/TVCG.2022.3156949
X. Ma et al., “A Novel Generative Image Inpainting Model with Dense Gated Convolutional Network,” International journal of computers communications & control, vol. 18, no. 2, 2023. https://doi.org/10.15837/ijccc.2023.2.5088.
Y. Chen et al., “RNON: image inpainting via repair network and optimization network,” International Journal of Machine Learning and Cybernetics, vol. 14, no. 9, pp. 2945–2961, 2023. https://doi.org/10.1007/s13042-023-01811-y.
J. Wang et al., “Self-Prior Guided Pixel Adversarial Networks for Blind Image Inpainting,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 10, pp. 12377–12393, 2023. DOI: 10.1109/TPAMI.2023.3284431
A. Mohammed and R. Kora, “A comprehensive review on ensemble deep learning: Opportunities and challenges,” Journal of King Saud University-Computer and Information Sciences, vol. 35, no. 2, pp. 757–774. 2023. https://doi.org/10.1016/j.jksuci.2023.01.014
J. Jam et al., “A comprehensive review of past and present image inpainting methods,” Computer vision and image understanding, vol. 203, p. 103147, 2021. https://doi.org/10.1016/j.cviu.2020.103147
O. Elharrouss et al., “Image Inpainting: A Review,” Neural Processing Letters, vol. 51, no. 2, pp. 2007–2028, 2020.
L. Trevisan de Souza et al., “A review on Generative Adversarial Networks for image generation,” Computers & Graphics, vol. 114, pp. 13–25, 2023. https://doi.org/10.1016/j.cag.2023.05.010
X. Zhang et al., “Image inpainting based on deep learning: A review,” Information Fusion, vol. 90, pp. 74–94, 2023. https://doi.org/10.1016/j.inffus.2022.08.033.
W. Quan et al., “Deep Learning-Based Image and Video Inpainting: A Survey,” International Journal of Computer Vision, 2024. https://doi.org/10.1007/s11263-023-01977-6.
Z. Yan et al., “Shift-Net: Image Inpainting via Deep Feature Rearrangement,” in Proceedings of the European conference on computer vision (ECCV), 2018. https://doi.org/10.1007/978-3-030-01264-9_1
G. Liu et al., “Image Inpainting for Irregular Holes Using Partial Convolutions,” in Proceedings of the European conference on computer vision (ECCV), pp. 85–100, 2018. https://doi.org/10.1007/978-3-030-01252-6_6
C. Xie et al., “Image Inpainting With Learnable Bidirectional Attention Maps,” in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 8857–8866, 2019. DOI: 10.1109/ICCV.2019.00895
C. Chen et al., “Rethinking Atrous Convolution for Semantic Image Segmentation,” 2017.
Y. Zhang et al., “Art image inpainting via embedding multiple attention dilated convolutions,” Multimedia Tools and Applications, vol. 83, no. 12, pp. 36455–36468, 2023. https://doi.org/10.1007/s11042-023-15285-1
H. Liu et al., “Rethinking Image Inpainting via a Mutual Encoder-Decoder with Feature Equalizations,” in 16th European Conference on Computer Vision, pp. 725–741, 2020. https://doi.org/10.1007/978-3-030-58536-5_4
J. Qin et al., “Multi-scale attention network for image inpainting,” Computer Vision and Image Understanding, vol. 204, p. 103155, 2021. https://doi.org/10.1016/j.cviu.2020.103155
Y. Chen et al., “DARGS: Image inpainting algorithm via deep attention residuals group and semantics,” Journal of King Saud University-Computer and Information Sciences, vol. 35, no. 6, p. 101567, 2023. https://doi.org/10.1016/j.jksuci.2023.101567
S. Ge et al., “Occluded Face Recognition in the Wild by Identity-Diversity Inpainting,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 30, no. 10, pp. 3387–3397, 2020. DOI: 10.1109/TCSVT.2020.2967754
H. Li et al., “Recovery-Based Occluded Face Recognition by Identity-Guided Inpainting,” Sensors, vol. 24, no. 2, p. 394, 2024. https://doi.org/10.3390/s24020394
C. Li et al., “Occluded Face Recognition by Identity-Preserving Inpainting,” Cognitive Internet of Things: Frameworks, Tools and Applications, pp. 427–437, 2020. https://doi.org/10.1007/978-3-030-04946-1_41
Y. Yang et al., “Generative face inpainting hashing for occluded face retrieval,” International Journal of Machine Learning and Cybernetics, vol. 14, no. 5, pp. 1725–1738, 2023. https://doi.org/10.1007/s13042-022-01723-3
A. Chen et al., “Occlusion-aware face inpainting via generative adversarial networks,” in 2017 IEEE International Conference on Image Processing (ICIP), pp. 1202–1206, 2017. DOI: 10.1109/ICIP.2017.8296472
W. Jiang et al., “A new occluded face recognition framework with combination of both Deocclusion and feature filtering methods,” Multimedia Tools and Applications, vol. 81, no. 23, pp. 33867–33896, 2022. https://doi.org/10.1007/s11042-022-12851-x
X. Yuan and I. K. Park, “Face De-Occlusion Using 3D Morphable Model and Generative Adversarial Network,” in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 10061–10070, 2019. DOI: 10.1109/ICCV.2019.01016
Z. Li et al., “Face Inpainting via Nested Generative Adversarial Networks,” IEEE Access, vol. 7, pp. 155462–155471, 2019. DOI: 10.1109/ACCESS.2019.2949614
D. Kim and U. Park, “Guidance Information Assisted Reconstruction of Masked Faces,” IEEE Access, vol. 11, pp. 97014–97023, 2023. DOI: 10.1109/ACCESS.2023.3311717
I. Lee et al., “Latent-OFER: Detect, Mask, and Reconstruct with Latent Vectors for Occluded Facial Expression Recognition,” in 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 1536–1546, 2023. DOI: 10.1109/ICCV51070.2023.00148
L. Li et al., “Mask-FPAN: Semi-supervised face parsing in the wild with de-occlusion and UV GAN,” Computers & Graphics, vol. 116, pp. 185–193, 2023. https://doi.org/10.1016/j.cag.2023.08.003
J. Xu et al., “Personalized Face Inpainting with Diffusion Models by Parallel Visual Attention,” in 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pp. 5420–5430, 2024. DOI: 10.1109/WACV57701.2024.00535
X. Yin et al., “Segmentation-Reconstruction-Guided Facial Image De-occlusion,” in 2023 IEEE 17th International Conference on Automatic Face and Gesture Recognition (FG), pp. 1–8, 2023. DOI: 10.1109/FG57933.2023.10042570
K. He et al., “Deep Residual Learning for Image Recognition,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770–778, 2016. DOI: 10.1109/CVPR.2016.90
T. Lin et al., “A survey of transformers,” AI Open, vol. 3, pp. 111–132, 2022. https://doi.org/10.1016/j.aiopen.2022.10.001
O. K. Oyedotun, K. Al Ismaeil, and D. Aouada, “Training very deep neural networks: Rethinking the role of skip connections,” Neurocomputing, vol. 441, pp. 105–117, 2021. https://doi.org/10.1016/j.neucom.2021.02.004
A. E. Orhan and X. Pitkow, “Skip Connections Eliminate Singularities,” arXiv preprint arXiv:1701.09175, 2017.
H. Li, “Visualizing the Loss Landscape of Neural Nets,” in Advances in Neural Information Processing Systems 31 (NIPS 2018), 2017.
G. Lu et al., “Optimizing Depthwise Separable Convolution Operations on GPUs,” IEEE Transactions on Parallel and Distributed Systems, vol. 33, no. 1, pp. 70–87, 2022. DOI: 10.1109/TPDS.2021.3084813
J. Johnson et al., “Perceptual Losses for Real-Time Style Transfer and Super-Resolution,” in Computer Vision - ECCV 2016, pp. 694–711, 2016.
https://doi.org/10.48550/arXiv.1603.08155
K. Simonyan and A. Zisserman, “Very Deep Convolutional Networks for Large-Scale Image Recognition,” arXiv, 2014. https://doi.org/10.48550/arXiv.1409.1556
R. Voo et al., “Delving into High-Quality Synthetic Face Occlusion Segmentation Datasets,” in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 4710–4719, 2022. DOI: 10.1109/CVPRW56347.2022.00517
R. Geirhos et al., “Shortcut learning in deep neural networks,” Nature Machine Intelligence, vol. 2, no. 11, pp. 665–673, 2020. https://doi.org/10.1038/s42256-020-00257-z
X. Bai et al., “Explainable deep learning for efficient and robust pattern recognition: A survey of recent developments,” Pattern Recognition, vol. 120, p. 108102, 2021. https://doi.org/10.1016/j.patcog.2021.108102
R. Selvaraju et al., “Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization,” in 2017 IEEE International Conference on Computer Vision (ICCV), pp. 618–626, 2017. DOI: 10.1109/ICCV.2017.74
T. Huang, “IntroVAE: Introspective Variational Autoencoders for Photographic Image Synthesis,” in Advances in neural information processing systems, vol. 31, 2018. https://doi.org/10.48550/arXiv.1807.06358
J. Yu et al., “Free-Form Image Inpainting With Gated Convolution,” in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 4470–4479, 2019. DOI: 10.1109/ICCV.2019.00457
Z. Yi et al., “Contextual Residual Aggregation for Ultra High-Resolution Image Inpainting,” in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 7505–7514, 2020. DOI: 10.1109/CVPR42600.2020.00753