Performance evaluation of emotion recognition algorithms in Brazilian Portuguese language audios
Keywords:
Emotion recognition., Portuguese language audios., Acoustic features., Affective computing., Algorithm performance comparison.Abstract
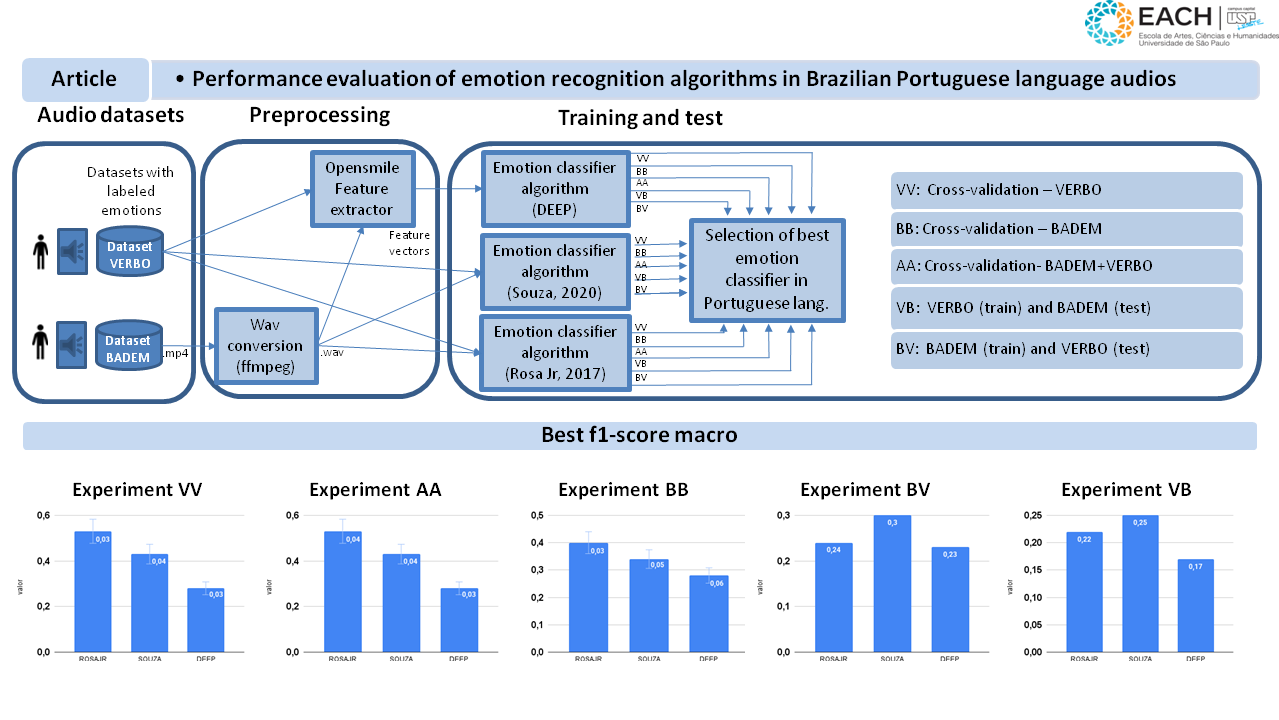
Emotion recognition in humans is a multidisciplinary field that involves analyzing several types of data. Computational techniques in pattern recognition and machine learning have been applied to emotion analysis using various modalities, including gestures and facial expressions (visual signals), the lexical content of spoken or written language (textual signals), and the sound of speech (acoustic signals). Acoustic analysis leverages characteristics of speech such as frequency, tone, intensity, and harmonics, which are strongly linked to emotional states. This type of acoustic analysis has numerous applications, such as examining relationships through dialogue, enhancing human-machine interaction, and detecting psychiatric disorders, among others. While the performance of audio-based emotion recognition algorithms is well explored in several languages, there is a notable gap in the literature regarding emotion recognition in audio dialogues in Portuguese. This article aims to address this gap by evaluating the performance of three algorithms that use different models to recognize discrete emotions, happiness, anger, fear, disgust, sadness, surprise, and neutral, in Brazilian Portuguese audios. The results indicate that significant advancements are still needed for effective emotion recognition in this language.
Among the algorithms studied, the maximum accuracy and F1-score achieved were 0.53, and no peer-reviewed publications were found, specifically on emotion recognition in Portuguese involving multiple datasets.
Downloads
References
M. Nasir, B. R. Baucom, P. Georgiou, and S. Narayanan, “Predicting couple therapy outcomes based on speech acoustic features.,” PloS one, vol. 12, no. 9, p. e0185123, 2017. doi: 10.1371/journal.pone.0185123.
X. Li and M. Akagi, “Multilingual speech emotion recognition system based on a three-layer model,” in Proc. Annu. Conf. Int. Speech.
Commun. Assoc., INTERSPEECH (Morgan N., Georgiou P., Morgan N., Narayanan S., and Metze F., eds.), vol. 08-12-September-2016,
pp. 3608–3612, International Speech and Communication Association, 2016. doi: 10.21437/Interspeech.2016-645.
O. Verkholyak, H. Kaya, and A. Karpov, “Modeling short-term and long-term dependencies of the speech signal for paralinguistic emotion classification,” SPIIRAS Proceedings, vol. 18, no. 1, pp. 30–56, 2019. doi: 10.15622/sp.18.1.30-56.
B. Jin and G. Liu, “Speech emotion recognition based on hyper-prosodic features,” in Proc. - Int. Conf. Comput. Technol., Electron. Commun., ICCTEC, pp. 82–87, Institute of Electrical and Electronics Engineers Inc., 2017. doi: 10.1109/ICCTEC.2017.00027.
G. Tamuleviˇcius, G. Korvel, A. Yayak, P. Treigys, J. Bernataviˇcien˙e, and B. Kostek, “A study of cross-linguistic speech emotion recognition based on 2D feature spaces,” Electronics (Switzerland), vol. 9, no. 10, pp. 1–13, 2020. doi: 10.3390/electronics9101725.
H. Li, B. Baucom, and P. Georgiou, “Linking emotions to behaviors through deep transfer learning,” PeerJ Computer Science, vol. 2020,
no. 1, pp. 1–32, 2020. doi: 10.7717/peerj-cs.246.
R. Ashrafidoost, S. Setayeshi, and A. Sharifi, “Recognizing emotional state changes using speech processing,” in 2016 European Modelling Symposium (EMS), pp. 41–46, Nov. 2016. doi: 10.1109/EMS.2016.017.
J. da Rosa Jr, “Reconhecimento automático de emoções através da voz,”. 2017. Undergraduate thesis. Universidade Federal de Santa Catarina. doi not available.
G. A. Campos and L. da S. Moutinho, “Deep: Uma arquitetura para reconhecer emoção com base no espectro sonoro da voz de falantes da língua portuguesa,” 2020. Undergraduate thesis. Universidade de Brasília. doi not available.
R. M. de Souza, “Reconhecimento de emoções através da fala utilizando redes neurais,” 2020. Undergraduate thesis. Universidade Federal de Santa Catarina. doi not available.
C. Do˘gdu, T. Kessler, D. Schneider, M. Shadaydeh, and S. R. Schwein-berger, “A comparison of machine learning algorithms and feature sets for automatic vocal emotion recognition in speech,” Sensors, vol. 22, no. 19, 2022. doi: 10.3390/s22197561.
F. Burkhardt, A. Paeschke, M. Rolfes, W. F. Sendlmeier, and B. Weiss, “A database of german emotional speech,” in Interspeech, pp. 1517–1520, ISCA, 2005. doi: 10.21437/Interspeech.2005-446.
F. Eyben, M. Wöllmer, and B. Schuller, “Opensmile: the munich versatile and fast open-source audio feature extractor,” in Proceedings of the 18th ACM International Conference on Multimedia, MM ’10, (New York, NY, USA), p. 1459–1462, Association for Computing Machinery, 2010. doi: 10.1145/1873951.1874246.
B. T. Atmaja and M. Akagi, “On the differences between song and speech emotion recognition: Effect of feature sets, feature types, and classifiers,” in 2020 IEEE REGION 10 CONFERENCE (TENCON), pp. 968–972, Nov 2020. doi:10.1109/TENCON50793.2020.9293852.
S. R. Livingstone and F. A. Russo, “The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English,” PLOS ONE, vol. 13, pp. 1–35, 05 2018. doi: 10.1371/journal.pone.0196391.
T. Giannakopoulos, “pyAudioAnalysis: An Open-Source Python Library for Audio Signal Analysis,” PloS one, vol. 10, no. 12, 2015. doi:
1371/journal.pone.0144610.
B. McFee, C. Raffel, D. Liang, D. Ellis, M. Mcvicar, E. Battenberg, and O. Nieto, “librosa: Audio and Music Signal Analysis in Python,”
pp. 18–24, 01 2015. doi: 10.25080/Majora-7b98e3ed-003.
P. Kannadaguli and V. Bhat, “Comparison of hidden markov model and artificial neural network based machine learning techniques using DDMFCC vectors for emotion recognition in Kannada,” 2019. doi: 10.1109/WIECON-ECE48653.2019.9019936.
J. Gondohanindijo, E. Noersasongko, Pujiono, Muljono, A. Z. Fanani, Affandy, and R. S. Basuki, “Comparison method in indonesian emotion speech classification,” p. 230 – 235, 2019. doi: 10.1109/ISEMANTIC.2019.8884298.
ffmpeg.org, “FFmpeg - a complete, cross-platform solution to record, convert and stream audio and video.” https://ffmpeg.org/, 2024. Accessed: 2024-09-07.
J. R. Torres Neto, G. P. Filho, L. Y. Mano, and J. Ueyama, “VERBO: Voice Emotion Recognition dataBase in Portuguese Language,” Journal of Computer Science, vol. 14, pp. 1420–1430, Nov 2018. doi: 10.3844/jcssp.2018.1420.1430.
L. M. F. Carlos, “A criação de um dataset audiovisual brasileiro de expressões emocionais,” Master’s thesis, Paradigma Centro de Ciências e Tecnologia do Comportamento, 2022. doi not available.
FILEFORMAT.INFO, “The wave file format.” https://www.fileformat.info/format/wave/corion.htm, 2024. Accessed: 2024-09-07.
“Information technology – coding of audio-visual objects – part 14: MP4 file format,” Standard ISO/IEC 14496-14:2003, International Organization for Standardization, 2003. Accessed: 2024-09-07.
P. Crewson, “Applied statistics handbook,” AcaStat Software, vol. 1, pp. 103–123, 2006. doi not available.
M. Sokolova and G. Lapalme, “A systematic analysis of performance measures for classification tasks,” Information Processing
and Management, vol. 45, no. 4, pp. 427–437, 2009. doi: 10.1016/j.ipm.2009.03.002.
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Van-
derplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay, “Scikit-Learn: Machine Learning in Python,” Journal of
Machine Learning Research, vol. 12, p. 2825–2830, nov 2011. doi: 10.5555/1953048.2078195.