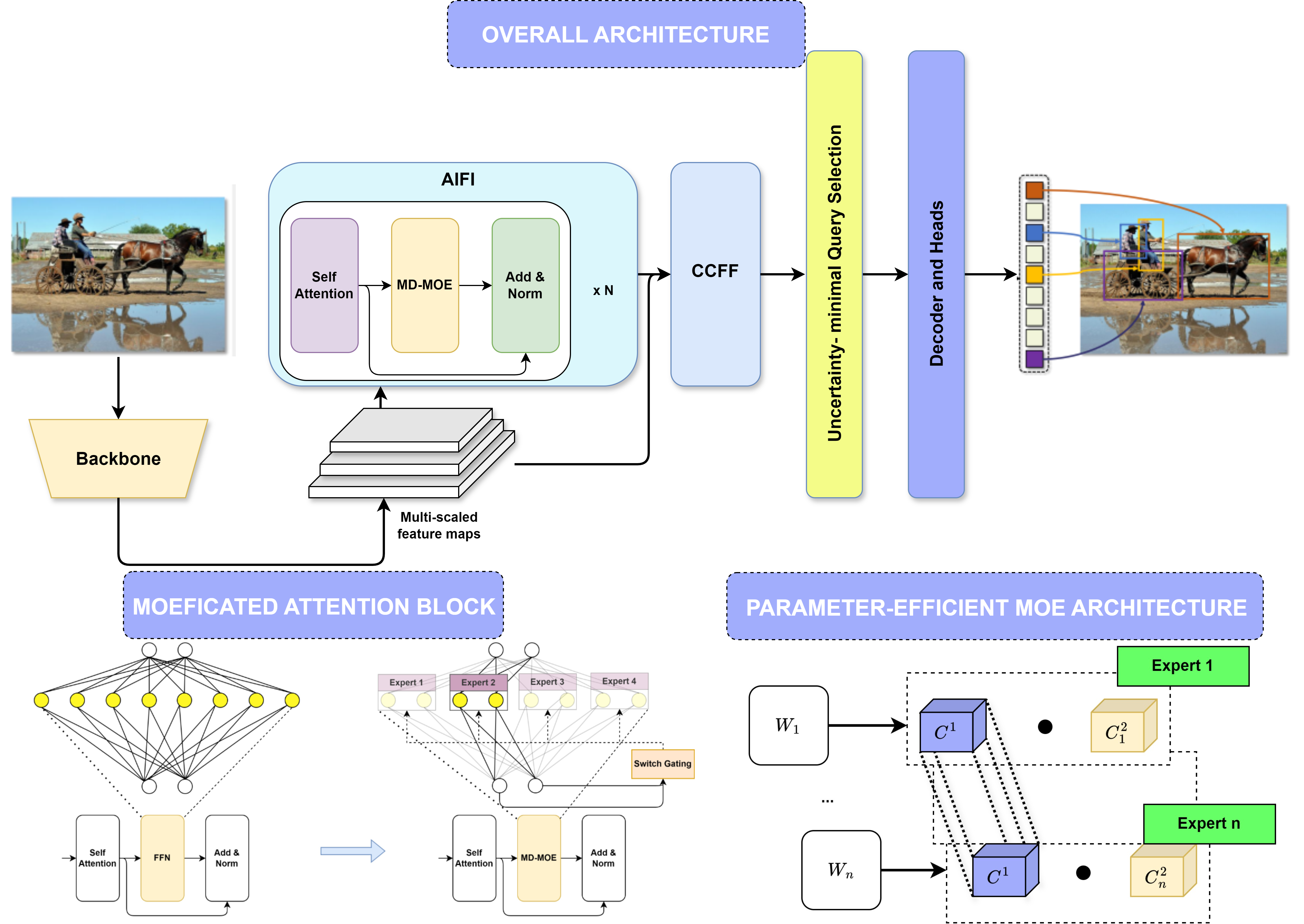
Enhancing RT-DETR Efficiency with Mixture of Experts Approach and Matrix Decomposition
Keywords:
object detection, model compression, transformer, mixture of experts, matrix decomposition, deep learningAbstract
In real-time object detection, convolutional neural networks (CNNs) have traditionally dominated the field. Recently, however, RT-DETR - a transformer-based object detection model - has emerged as a competitor to the CNN-based YOLO series by tackling limitations introduced by non-maximum suppression (NMS) in YOLO. Despite its strong potential, RT-DETR requires extensive runtime optimizations, such as conversion to a TensorRT environment, to achieve competitive processing speeds. Additionally, RT-DETR’s scaling approach focuses solely on adjustments within the decoder stage. In this paper, we propose a novel enhancement by integrating Mixture of Experts (MoE) and matrix decomposition techniques into RT-DETR’s encoder stage. This enhanced encoder significantly reduces computational complexity while preserving accuracy. Our model achieves a 50% reduction in FLOPs of encoder for a 640x640 input size, with only a minimal 0.4% drop in average precision (AP) on the COCO dataset, compared to the original RT-DETR. The official implementation code of our method is available at https://github.com/quoccuonglqd/RT-DETR
Downloads
References
J. Redmon, “You only look once: Unified, real-time object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, doi: https://doi.org/10.1109/cvpr.2016.91.
Y. Zhao, W. Lv, S. Xu, J. Wei, G. Wang, Q. Dang, Y. Liu, and J. Chen, “Detrs beat yolos on real-time object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 16 965–16 974, doi: https://doi.org/10.1109/cvpr52733.2024. 01605.
X. Hou, M. Liu, S. Zhang, P. Wei, and B. Chen, “Salience detr: Enhancing detection transformer with hierarchical salience filtering refinement,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 17 574–17 583, doi: https://doi.org/10.1109/cvpr52733.2024.01664.
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable detr: Deformable transformers for end-to-end object detection,” in International Conference on Learning Representations, doi: https://doi.org/10. 48550/arXiv.2010.04159.
F. Li, A. Zeng, S. Liu, H. Zhang, H. Li, L. Zhang, and L. M. Ni, “Lite detr: An interleaved multi-scale encoder for efficient detr,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 18 558–18 567, doi: https://doi.org/10. 1109/cvpr52729.2023.01780.
R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton, “Adaptive mixtures of local experts,” Neural computation, vol. 3, no. 1, pp. 79–87, 1991, doi: https://doi.org/10.1162/neco.1991.3.1.79.
T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft coco: Common objects in context,” in Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13. Springer, 2014, pp. 740–755, doi: https://doi.org/10.1007/ 978-3-319-10602-1_48.
S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,” IEEE transactions on pattern analysis and machine intelligence, vol. 39, no. 6, pp. 1137–1149, 2016, doi: https://doi.org/10.1109/tpami.2016.2577031.
K. He, G. Gkioxari, P. Dollár, and R. Girshick, “Mask r-cnn,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2961–2969, doi: https://doi.org/10.1109/iccv.2017.322.
W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg, “Ssd: Single shot multibox detector,” in Computer Vision– ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14. Springer, 2016, pp. 21–37, doi: https://doi.org/10.1007/978-3-319-46448-0_2.
T.-Y. Ross and G. Dollár, “Focal loss for dense object detection,” in proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2980–2988, doi: https://doi.org/10.1109/iccv.2017.324.
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-toend object detection with transformers. in eccv,” Springer, vol. 1, no. 2, p. 4, 2020, doi: https://doi.org/10.1007/ 978-3-030-58452-8_13.
D. Alexey, “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv: 2010.11929, 2020, doi: https: //doi.org/10.48550/arXiv.2010.11929.
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable detr: Deformable transformers for end-to-end object detection,” arXiv preprint arXiv:2010.04159, 2020, doi: https://doi.org/10.48550/arXiv. 2010.04159.
F. Li, H. Zhang, S. Liu, J. Guo, L. M. Ni, and L. Zhang, “Dn-detr: Accelerate detr training by introducing query denoising,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 13 619–13 627, doi: https://doi.org/10.1109/cvpr52688.2022. 01325.
Q. Chen, X. Chen, J. Wang, S. Zhang, K. Yao, H. Feng, J. Han, E. Ding, G. Zeng, and J. Wang, “Group detr: Fast detr training with group-wise one-to-many assignment,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 6633–6642, doi: https://doi. org/10.1109/iccv51070.2023.00610.
D. Meng, X. Chen, Z. Fan, G. Zeng, H. Li, Y. Yuan, L. Sun, and J. Wang, “Conditional detr for fast training convergence,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 3651– 3660, doi: https://doi.org/10.1109/iccv48922.2021.00363.
Y. Wang, X. Zhang, T. Yang, and J. Sun, “Anchor detr: Query design for transformer-based detector,” in Proceedings of the AAAI conference on artificial intelligence, vol. 36, no. 3, 2022, pp. 2567–2575, doi: https: //doi.org/10.1609/aaai.v36i3.20158.
H. Zhang, F. Li, S. Liu, L. Zhang, H. Su, J. Zhu, L. M. Ni, and H.- Y. Shum, “Dino: Detr with improved denoising anchor boxes for endto-end object detection,” arXiv preprint arXiv:2203.03605, 2022, doi: https://doi.org/10.48550/arXiv.2203.03605.
Z. Yao, J. Ai, B. Li, and C. Zhang, “Efficient detr: improving end-toend object detector with dense prior,” arXiv preprint arXiv:2104.01318, 2021, doi: https://doi.org/10.48550/arXiv.2104.01318.
H. Li, A. Kadav, I. Durdanovic, H. Samet, and H. P. Graf, “Pruning filters for efficient convnets,” arXiv preprint arXiv:1608.08710, 2016, doi: https://doi.org/10.48550/arXiv.1608.08710.
S. Han, J. Pool, J. Tran, and W. Dally, “Learning both weights and connections for efficient neural network,” Advances in neural information processing systems, vol. 28, 2015, doi: https://doi.org/10.48550/arXiv. 1506.02626.
P. Molchanov, S. Tyree, T. Karras, T. Aila, and J. Kautz, “Pruning convolutional neural networks for resource efficient inference,” arXiv preprint arXiv:1611.06440, 2016, doi: https://doi.org/10.48550/arXiv. 1611.06440.
Y. He, J. Lin, Z. Liu, H. Wang, L.-J. Li, and S. Han, “Amc: Automl for model compression and acceleration on mobile devices,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 784– 800, doi: https://doi.org/10.1007/978-3-030-01234-2_48.
T. Liang, J. Glossner, L. Wang, S. Shi, and X. Zhang, “Pruning and quantization for deep neural network acceleration: A survey,” Neurocomputing, vol. 461, pp. 370–403, 2021, doi: https://doi.org/10.1016/j. neucom.2021.07.045.
P. Micikevicius, S. Narang, J. Alben, G. Diamos, E. Elsen, D. Garcia, B. Ginsburg, M. Houston, O. Kuchaiev, G. Venkatesh et al., “Mixed precision training,” arXiv preprint arXiv:1710.03740, 2017, doi: https: //doi.org/10.48550/arXiv.1710.03740.
Q. Li, S. Jin, and J. Yan, “Mimicking very efficient network for object detection,” in Proceedings of the ieee conference on computer vision and pattern recognition, 2017, pp. 6356–6364, doi: https://doi.org/10. 1109/cvpr.2017.776.
L. Qi, J. Kuen, J. Gu, Z. Lin, Y. Wang, Y. Chen, Y. Li, and J. Jia, “Multiscale aligned distillation for low-resolution detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 14 443–14 453, doi: https://doi.org/10.1109/cvpr46437.2021. 01421.
R. Sun, F. Tang, X. Zhang, H. Xiong, and Q. Tian, “Distilling object detectors with task adaptive regularization,” arXiv preprint arXiv:2006.13108, 2020, doi: https://doi.org/10.48550/arXiv. 2006.13108.
Z. Yang, Z. Li, X. Jiang, Y. Gong, Z. Yuan, D. Zhao, and C. Yuan, “Focal and global knowledge distillation for detectors,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 4643–4652, doi: https://doi.org/10.1109/cvpr52688.2022. 00460.
R. Mehta and C. Ozturk, “Object detection at 200 frames per second,” in Proceedings of the European Conference on Computer Vision (ECCV) Workshops, 2018, pp. 0–0, doi: https://doi.org/10.1007/ 978-3-030-11021-5_41.
Z. Zheng, R. Ye, P. Wang, D. Ren, W. Zuo, Q. Hou, and M.-M. Cheng, “Localization distillation for dense object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 9407–9416, doi: https://doi.org/10.1109/cvpr52688.2022. 00919.
P. De Rijk, L. Schneider, M. Cordts, and D. Gavrila, “Structural knowledge distillation for object detection,” Advances in Neural Information Processing Systems, vol. 35, pp. 3858–3870, 2022, doi: https://doi.org/10.48550/arXiv.2211.13133.
J. Guo, K. Han, Y. Wang, H. Wu, X. Chen, C. Xu, and C. Xu, “Distilling object detectors via decoupled features,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 2154–2164, doi: https://doi.org/10.1109/cvpr46437.2021.00219.
G. Li, X. Li, Y. Wang, S. Zhang, Y. Wu, and D. Liang, “Knowledge distillation for object detection via rank mimicking and predictionguided feature imitation,” in Proceedings of the AAAI conference on artificial intelligence, vol. 36, no. 2, 2022, pp. 1306–1313, doi: https: //doi.org/10.1609/aaai.v36i2.20018.
X. Dai, Z. Jiang, Z. Wu, Y. Bao, Z. Wang, S. Liu, and E. Zhou, “General instance distillation for object detection,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 7842–7851, doi: https://doi.org/10.1109/cvpr46437.2021.00775.
H. Kuang, L. Chen, L. L. H. Chan, R. C. Cheung, and H. Yan, “Feature selection based on tensor decomposition and object proposal for nighttime multiclass vehicle detection,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 49, no. 1, pp. 71–80, 2018, doi: https: //doi.org/10.1109/tsmc.2018.2872891.
X. Zhang, Y. Gong, C. Qiao, and W. Jing, “Multiview deep learning based on tensor decomposition and its application in fault detection of overhead contact systems,” The visual computer, vol. 38, no. 4, pp. 1457–1467, 2022, doi: https://doi.org/10.1007/s00371-021-02080-y.
L. Meneghetti, N. Demo, and G. Rozza, “A proper orthogonal decomposition approach for parameters reduction of single shot detector networks,” in 2022 IEEE International Conference on Image Processing (ICIP). IEEE, 2022, pp. 2206–2210, doi: https://doi.org/10.1109/icip46576.2022.9897513
L. Huyan, Y. Li, D. Jiang, Y. Zhang, Q. Zhou, B. Li, J. Wei, J. Liu, Y. Zhang, P. Wang et al., “Remote sensing imagery object detection model compression via tucker decomposition,” Mathematics, vol. 11, no. 4, p. 856, 2023, doi: https://doi.org/10.3390/math11040856.
F. Chollet, “Xception: Deep learning with depthwise separable convolutions,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1251–1258, doi: https://doi.org/10.1109/ cvpr.2017.195.
T. Zhang, G.-J. Qi, B. Xiao, and J. Wang, “Interleaved group convolutions,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 4373–4382, doi: https://doi.org/10.1109/iccv.2017.469.
S. Xie, R. Girshick, P. Dollár, Z. Tu, and K. He, “Aggregated residual transformations for deep neural networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1492– 1500, doi: https://doi.org/10.1109/cvpr.2017.634.
A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: efficient convolutional neural networks for mobile vision applications (2017),” arXiv preprint arXiv:1704.04861, vol. 126, 2017, doi: https://doi.org/10.48550/arXiv. 1704.04861.
M. Tan and Q. Le, “Efficientnet: Rethinking model scaling for convolutional neural networks,” in International conference on machine learning. PMLR, 2019, pp. 6105–6114, doi: https://doi.org/10.48550/ arXiv.1905.11946.
K. Han, Y. Wang, Q. Tian, J. Guo, C. Xu, and C. Xu, “Ghostnet: More features from cheap operations,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 1580– 1589, doi: https://doi.org/10.1109/cvpr42600.2020.00165.
H. Law and J. Deng, “Cornernet: Detecting objects as paired keypoints,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 734–750, doi: https://doi.org/10.1007/s11263-019-01204-1.
K. Duan, S. Bai, L. Xie, H. Qi, Q. Huang, and Q. Tian, “Centernet: Keypoint triplets for object detection,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 6569–6578, doi: https://doi.org/10.1109/iccv.2019.00667.
T. Wang, X. Zhu, J. Pang, and D. Lin, “Fcos3d: Fully convolutional onestage monocular 3d object detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 913–922, doi: https://doi.org/10.1109/iccvw54120.2021.00107.
F. D. Keles, P. M. Wijewardena, and C. Hegde, “On the computational complexity of self-attention,” in International Conference on Algorithmic Learning Theory. PMLR, 2023, pp. 597–619, doi: https: //doi.org/10.48550/arXiv.2209.04881.
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,” Journal of Machine Learning Research, vol. 23, no. 120, pp. 1–39, 2022, doi: https://doi.org/10.48550/arXiv.2101.03961.
Y. J. Kim, A. A. Awan, A. Muzio, A. F. C. Salinas, L. Lu, A. Hendy, S. Rajbhandari, Y. He, and H. H. Awadalla, “Scalable and efficient moe training for multitask multilingual models,” arXiv preprint arXiv:2109.10465, 2021, doi: https://doi.org/10.48550/arXiv. 2109.10465.
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255, doi: https://doi.org/10.1109/cvprw.2009.5206848.
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778, doi: https://doi.org/10.1109/ cvpr.2016.90.