Saliency-aware Spatio-temporal Modeling for Action Recognition on Unmanned Aerial Vehicles
Keywords:
Deep learning, action recognition, attention mechanism, unmanned aerial vehiclesAbstract
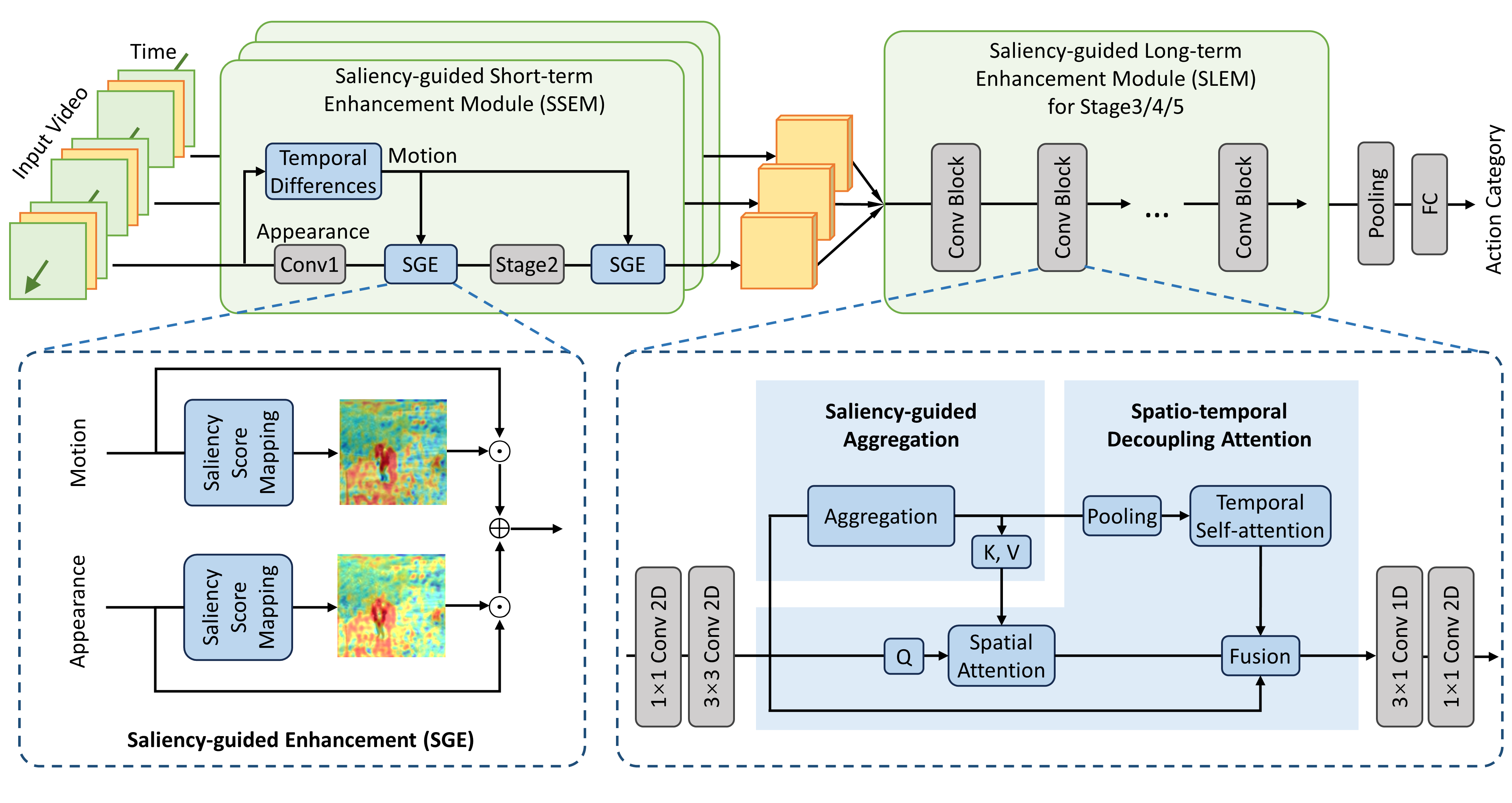
Action recognition on unmanned aerial vehicles (UAVs) must cope with complex backgrounds and focus on small targets. Existing methods usually use additional detectors to extract objects in each frame, and use the object sequence within boxes as the network input. However, for training, they rely on additional detection annotations, and for inference, the multi-stage paradigm increases the burden of deployment on UAV terminals. Therefore, we propose a saliency-aware spatio-temporal network (SaStNet) for UAV-based action recognition in an end-to-end manner. Specifically, the short-term and long-term motion information are captured progressively. For short-term modeling, a saliency-guided enhancement module is designed to learn attention scores for weighting the original features aggregated within neighboring frames. For long-term modeling, informative regions are first adaptively concentrated using a saliency-guided aggregation module. Then, a spatio-temporal decoupling attention mechanism is designed to focus on spatially salient regions and capture temporal relationships within all frames. Integrating these modules into classical backbones encourages the network to focus on moving targets, reducing interference from background noises. Extensive experiments and ablation studies are conducted on UAV-Human, Drone action, and something-something datasets. Compared to state-of-the-art methods, SaStNet achieves a 5.7% accuracy improvement on the UAV-Human dataset using 8-frame inputs.
Downloads
References
M. Barekatain, M. Mart´ ı, H.-F. Shih, S. Murray, K. Nakayama, Y. Mat suo, and H. Prendinger, “Okutama-Action: An aerial view video dataset for concurrent human action detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition workshops, 2017, pp. 28–35, doi:10.1109/CVPRW.2017.267.
A. G. Perera, Y. W. Law, and J. Chahl, “Drone-Action: An outdoor recorded drone video dataset for action recognition,” Drones, vol. 3, no. 4, p. 82, 2019, doi:10.3390/drones3040082.
A. G. Perera, Y. W. Law, T. T. Ogunwa, and J. Chahl, “A multiview point outdoor dataset for human action recognition,” IEEE Transac tions on Human-Machine Systems, vol. 50, no. 5, pp. 405–413, 2020, doi:10.1109/thms.2020.2971958.
J. Choi, G. Sharma, M. Chandraker, and J.-B. Huang, “Unsuper vised and semi-supervised domain adaptation for action recogni tion from drones,” in Proceedings of the IEEE Winter Confer ence on Applications of Computer Vision, 2020, pp. 1717–1726, doi:10.1109/WACV45572.2020.9093511.
U. Demir, Y. S. Rawat, and M. Shah, “TinyVIRAT: Low-resolution video action recognition,” in International Conference on Pattern Recognition, 2021, pp. 7387–7394, doi:10.1109/icpr48806.2021.9412541.
T. Li, J. Liu, W. Zhang, Y. Ni, W. Wang, and Z. Li, “UAV Human: A large benchmark for human behavior understanding with unmanned aerial vehicles,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2021, pp. 16266–16275, doi:10.1109/cvpr46437.2021.01600.
O. L. Barbed, P. Azagra, L. Teixeira, M. Chli, J. Civera, and A. C. Murillo, “Fine-grained pointing recognition for natural drone guidance,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2020, pp. 1040–1041, doi:10.1109/cvprw50498.2020.00528.
H. Gammulle, S. Denman, S. Sridharan, and C. Fookes, “Predicting the Future: A jointly learnt model for action anticipation,” in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 5562–5571, doi:10.1109/iccv.2019.00566.
H. Mliki, F. Bouhlel, and M. Hammami, “Human activity recognition from uav-captured video sequences,” Pattern Recognition, vol. 100, p. 107140, 2020, doi:10.1016/j.patcog.2019.107140 .
R. Xian, X. Wang, and D. Manocha, “MITFAS: Mutual infor mation based temporal feature alignment and sampling for aerial video action recognition,” in Proceedings of the IEEE Winter Con ference on Applications of Computer Vision, 2024, pp. 6625–6634, doi:10.1109/wacv57701.2024.00649.
M. Khan, J. Ahmad, A. El Saddik, W. Gueaieb, G. De Masi, and F. Karray, “Drone-HAT: Hybrid attention transformer for complex action recognition in drone surveillance videos,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2024, pp. 4713–4722.
M. Assefa, W. Jiang, K. Gedamu, G. Yilma, B. Kumeda, and M. Ayalew, “Self-supervised scene-debiasing for video representation learning via background patching,” IEEE Transactions on Multimedia, pp. 5500 5515, 2022, doi:10.1109/TMM.2022.3193559.
Y. Kong, Y. Wang, and A. Li, “Spatiotemporal saliency representation learning for video action recognition,” IEEE Transactions on Multime dia, vol. 24, pp. 1515–1528, 2021, doi:10.1109/tmm.2021.3066775.
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778, doi:10.1109/cvpr.2016.90.
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems, 2017, pp. 5998 6008, doi:10.48550/arXiv.1706.03762.
R. Goyal, S. Ebrahimi Kahou, V. Michalski, J. Materzynska, S. West phal, H. Kim, V. Haenel, I. Fruend, P. Yianilos, M. Mueller-Freitag et al., “The “something something” video database for learning and evaluating visual common sense,” in Proceedings of the IEEE in ternational conference on computer vision, 2017, pp. 5842–5850, doi:10.1109/iccv.2017.622.
J. Carreira and A. Zisserman, “Quo vadis, action recognition? A new model and the kinetics dataset,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, July 2017, doi:10.1109/cvpr.2017.502.
J. Lee-Thorp, J. Ainslie, I. Eckstein, and S. Ontanon, “FNet: Mixing tokens with fourier transforms,” arXiv preprint arXiv:2105.03824, 2021, doi:10.48550/arXiv.2105.03824.
D. Kothandaraman, T. Guan, X. Wang, S. Hu, M. Lin, and D. Manocha, “FAR: Fourier aerial video recognition,” in European Conference on Computer Vision, 2022, pp. 657–676, doi:10.1007/978-3-031-19836 6 37.
D. Kothandaraman, M. Lin, and D. Manocha, “Differentiable frequency based disentanglement for aerial video action recognition,” arXiv preprint arXiv:2209.09194, 2022, doi:10.48550/arXiv.2209.09194.
C. Feichtenhofer, “X3D: Expanding architectures for efficient video recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2020, pp. 203–213, doi:cvpr42600.2020.00028.
H. Fan, B. Xiong, K. Mangalam, Y. Li, Z. Yan, J. Malik, and C. Feicht enhofer, “Multiscale vision transformers,” in Proceedings of the IEEE international conference on computer vision, 2021, pp. 6824–6835, doi:10.1109/iccv48922.2021.00675.
X. Wang, R. Xian, T. Guan, C. M. de Melo, S. M. Nogar, A. Bera, and D. Manocha, “AZTR: Aerial video action recognition with auto zoom and temporal reasoning,” in 2023 IEEE Interna tional Conference on Robotics and Automation, 2023, pp. 1312–1318, doi:icra48891.2023.10160564.
G. Ch´eron, I. Laptev, and C. Schmid, “P-CNN: Pose-based cnn features for action recognition,” in Proceedings of the IEEE in ternational conference on computer vision, 2015, pp. 3218–3226, doi:10.1109/iccv.2015.368.
C. Dhiman, A. Varshney, and V. Vyapak, “AP-TransNet: A polarized transformer based aerial human action recognition framework,” Machine Vision and Applications, vol. 35, no. 3, p. 52, 2024, doi:10.1007/s00138 024-01535-1.
L. Wang, Z. Tong, B. Ji, and G. Wu, “TDN: Temporal difference networks for efficient action recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2021, pp. 1895 1904, doi:cvpr46437.2021.00193.
M. S. Ryoo, A. Piergiovanni, A. Arnab, M. Dehghani, and A. Angelova, “TokenLearner: What can 8 learned tokens do for images and videos?” arXiv preprint arXiv:2106.11297, 2021, doi:arXiv.2106.11297.
L. Wang, Y. Xiong, Z. Wang, Y. Qiao, D. Lin, X. Tang, and L. Van Gool, “Temporal Segment Networks: Towards good practices for deep action recognition,” in European conference on computer vision, 2016, pp. 20 36, doi:10.1007/978-3-319-46484-8 2 .
B. Zhou, A. Andonian, A. Oliva, and A. Torralba, “Temporal relational reasoning in videos,” in Proceedings of the European conference on computer vision, 2018, pp. 803–818, doi:10.1007/978-3-030-01246 5 49 .
J. Lin, C. Gan, and S. Han, “TSM: Temporal shift module for efficient video understanding,” in Proceedings of the IEEE in ternational conference on computer vision, 2019, pp. 7083–7093, doi:10.1109/iccv.2019.00718 .
Z. Liu, D. Luo, Y. Wang, L. Wang, Y. Tai, C. Wang, J. Li, F. Huang, and T. Lu, “TEINet: Towards an efficient architecture for video recognition,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 07, 2020, pp. 11669–11676, doi:10.1609/aaai.v34i07.6836.
Y. Li, B. Ji, X. Shi, J. Zhang, B. Kang, and L. Wang, “TEA: Temporal excitation and aggregation for action recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2020, pp. 909–918, doi:10.1109/cvpr42600.2020.00099.
X. Li, Y. Wang, Z. Zhou, and Y. Qiao, “SmallBigNet: Integrating core and contextual views for video classification,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2020, pp. 1092–1101, doi:10.1109/cvpr42600.2020.00117.
K. Li, X. Li, Y. Wang, J. Wang, and Y. Qiao, “CT-Net: Chan nel tensorization network for video classification,” arXiv preprint arXiv:2106.01603, 2021, doi:10.48550/arXiv.2106.01603.