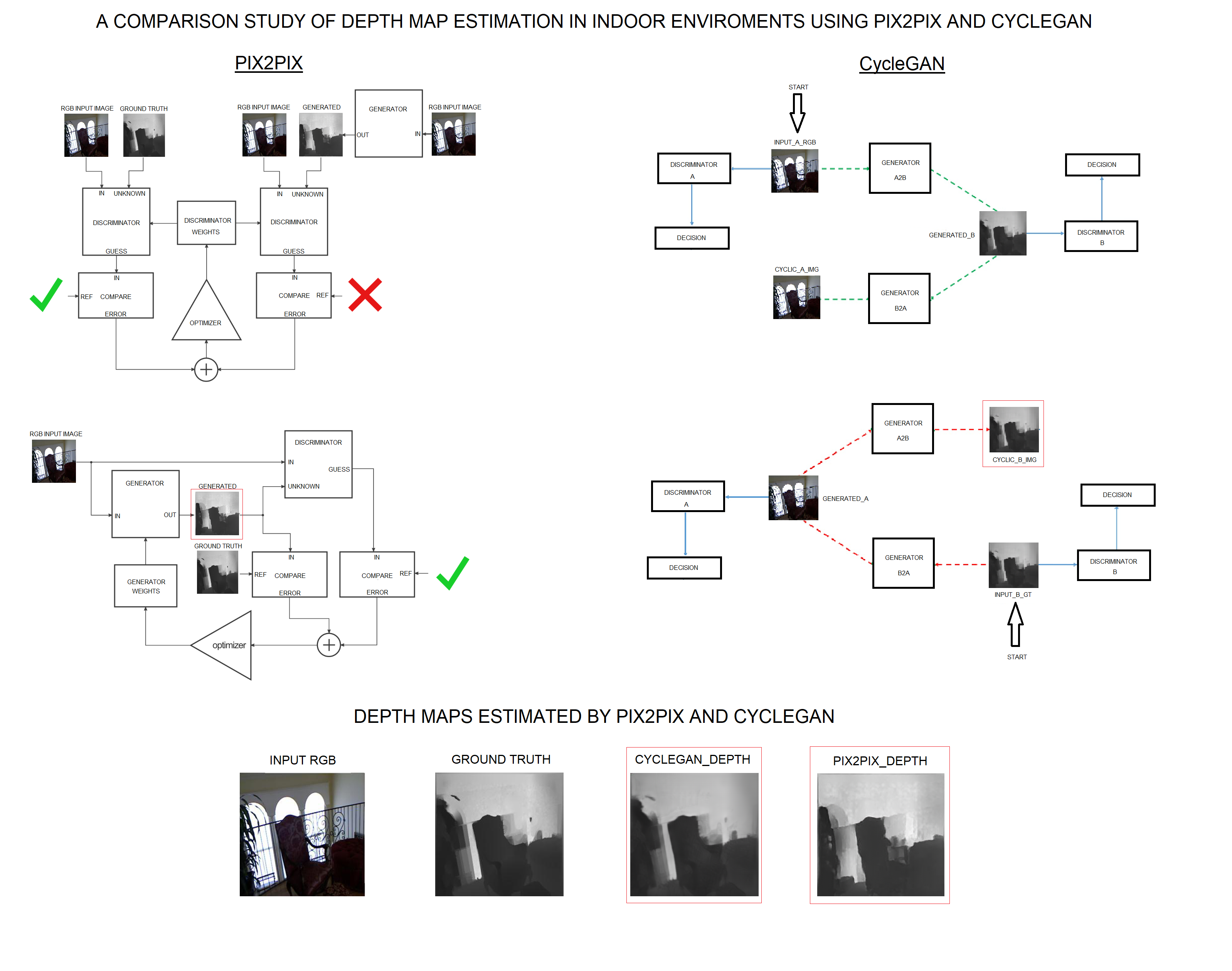
A comparison study of depth map estimation in indoor environments using pix2pix and CycleGAN
Keywords:
Depth map, navigation system for visually impaired people, generative adversarial networks, pix2pix, CycleGAN, MonoDepth2, DenseDepth, DepthNet_Resnet50, DepthNet_Resnet18Abstract
This article presents a Deep Learning-based approach for comparing automatic depth map estimation in indoor environments, with the aim of using them in navigation aid systems for visually impaired individuals. Depth map estimation is a laborious process, as most high-precision systems consist of complex stereo vision systems. The methodology utilizes Generative Adversarial Networks (GANs) techniques for generating depth maps from single RGB images. The study introduces methods for generating depth maps using pix2pix and CycleGAN. The major challenges still lie in the need to use large datasets, which are coupled with long training times. Additionally, a comparison of L1 Loss with a variation of the MonoDepth2 and DenseDepth systems was performed, using ResNet50 and ResNet18 as encoders, which are mentioned in this work, for comparison and validation of the presented method. The results demonstrate that CycleGAN is capable of generating more reliable maps compared to pix2pix and DepthNet_ResNet50, with an L1 Loss approximately 2,5 times smaller than pix2pix, approximately 2,4 times smaller than DepthNet_ResNet50, and approximately 14 times smaller than DepthNet_ResNet18.
Downloads
References
S. R. N. P. N. Zaman, “Single-image stereo depth estimation using gans,” aug 2023. Accessed: Aug. 09, 2023. [Online] Available:
https://sharanramjee.github.io/files/projects/cs231a.pdf.
K. G. Lore, K. Reddy, M. Giering, and E. A. Bernal, “Generative adversarial networks for depth map estimation from rgb video,” in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 1258–12588, IEEE, 2018.
R. Groenendijk, S. Karaoglu, T. Gevers, and T. Mensink, “On the benefit of adversarial training for monocular depth estimation,” Computer Vision and Image Understanding, vol. 190, p. 102848, 2020.
C. Godard, O. Mac Aodha, M. Firman, and G. J. Brostow, “Digging into self-supervised monocular depth estimation,” in Proceedings of the
IEEE/CVF international conference on computer vision, pp. 3828–3838, 2019.
H. Jiang, G. Larsson, M. M. G. Shakhnarovich, and E. Learned-Miller, “Self-supervised relative depth learning for urban scene understanding,” in Proceedings of the European Conference on Computer Vision (ECCV), pp. 19–35, 2018.
A. Saxena, M. Sun, and A. Y. Ng, “Make3d: Learning 3d scene structure from a single still image,” IEEE transactions on pattern analysis and
machine intelligence, vol. 31, no. 5, pp. 824–840, 2008.
D. Eigen, C. Puhrsch, and R. Fergus, “Depth map prediction from a single image using a multi-scale deep network,” in Advances in Neural
Information Processing Systems (Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, and K. Weinberger, eds.), vol. 27, Curran Associates, Inc., 2014.
C. Godard, O. Mac Aodha, and G. J. Brostow, “Unsupervised monocular depth estimation with left-right consistency,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 270–279, 2017.
A. Saxena, S. Chung, and A. Ng, “Learning depth from single monocular images,” Advances in neural information processing systems, vol. 18, 2005.
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets
in advances in neural information processing systems (nips),” Curran Associates, Inc. Red Hook, NY, USA, pp. 2672–2680, 2014.
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial networks,”
Communications of the ACM, vol. 63, no. 11, pp. 139–144, 2020.
P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros, “Image-to-image translation with conditional adversarial networks,” in Proceedings of the IEEE
conference on computer vision and pattern recognition, pp. 1125–1134, 2017.
T. Karras, S. Laine, and T. Aila, “A style-based generator architecture for generative adversarial networks,” in Proceedings of the IEEE/CVF
conference on computer vision and pattern recognition, pp. 4401–4410, 2019.
M. Ghafoorian, C. Nugteren, N. Baka, O. Booij, and M. Hofmann, “Elgan: Embedding loss driven generative adversarial networks for lane
detection,” in proceedings of the european conference on computer vision (ECCV) Workshops, pp. 0–0, 2018.
Y. Galama and T. Mensink, “Iterative gans for rotating visual objects„” aug 2018. Accessed: Aug. 09, 2023. [Online] Available: https://openreview.net/forum?id=HJ7rdGkPz.
A. Pilzer, D. Xu, M. Puscas, E. Ricci, and N. Sebe, “Unsupervised adversarial depth estimation using cycled generative networks,” in 2018
international conference on 3D vision (3DV), pp. 587–595, IEEE, 2018.
D.-h. Kwak and S.-h. Lee, “A novel method for estimating monocular depth using cycle gan and segmentation,” Sensors, vol. 20, no. 9, p. 2567, 2020.
X. K. T. Shimada, H. Nishikawa and H. Tomiyama, “Pix2pix-based monocular depth estimation for drones with optical flow on airsim,”
Sensors, vol. 22, no. 6, p. 2097, 2022.
S. M. P. Hambarde and A. Dhall, “Uw-gan: Single-image depth estimation and image enhancement for underwater images,” IEEE Transactions on Instrumentation and Measurement, vol. 70, pp. 1–12, 2021.
C. Hesse, “Iterative gans for rotating visual objects„” aug 2017. Accessed: Aug. 09, 2023. [Online] Available:
https://affinelayer.com/pix2pix/.
H. Bansal and A. Rathore, “Understanding and implementing cyclegan in tensorflow„” aug 2017. Accessed: Aug. 09, 2023. [Online] Available: https://hardikbansal.github.io/CycleGANBlog/.
J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” in Proceedings of the IEEE international conference on computer vision, pp. 2223–2232, 2017.
P. K. Nathan Silberman, Derek Hoiem and R. Fergus, “Indoor segmentation and support inference from rgbd images,” in ECCV, 2012.
I. Alhashim and P. Wonka, “High quality monocular depth estimation via transfer learning,” arXiv preprint arXiv:1812.11941, 2018.
D. Kim, W. Ka, P. Ahn, D. Joo, S. Chun, and J. Kim, “Global-local path networks for monocular depth estimation with vertical cutdepth,”
arXiv preprint arXiv:2201.07436, 2022.