ALAN-P: Dynamic action pruning for efficient navigation in complex environments
Keywords:
multi agent navigation, multi agent coordination, multi agent learning, simulationAbstract
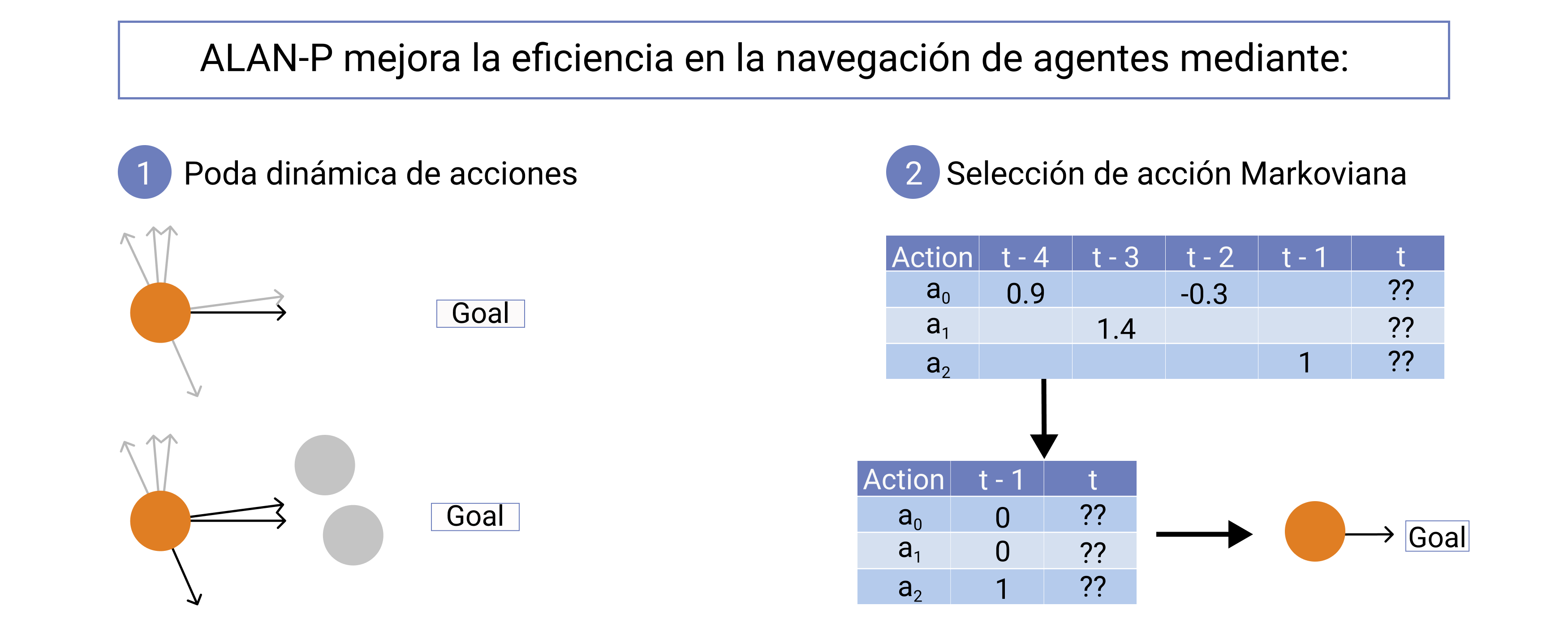
Multi-agent navigation consists on efficiently moving a set of agents from start to goal locations. This is a challenging task since most environments contain static and dynamic obstacles that can significantly restrict the movement of an agent. While existing methods, such as ALAN, can overcome some of these limitations by increasing the action space of the agents, their behavior can be suboptimal in many of the situations that agents can find themselves into. In this work, we propose ALAN-P, a multi agent local navigation method based on the ALAN framework, which improves the agent's behavior by dynamically adapting the action space to the agent's local conditions. The results of our experiments show that the proposed ALAN-P can lead to significant performance improvements over ALAN in a variety of challenging environments.
Downloads
References
J. Yu and S. M. LaValle, “Structure and intractability of optimal multirobot path planning on graphs,” in Twenty-Seventh AAAI Conference on Artificial Intelligence, 2013.
C. W. Reynolds, “Flocks, herds and schools: A distributed behavioral model,” in Proceedings of the 14th annual conference on Computer graphics and interactive techniques, 1987, pp. 25–34.
D. Helbing and P. Molnar, “Social force model for pedestrian dynamics,” Physical review E, vol. 51, no. 5, p. 4282, 1995.
I. Karamouzas, B. Skinner, and S. J. Guy, “Universal power law governing pedestrian interactions,” Physical review letters, vol. 113, no. 23, p. 238701, 2014.
A. Garcimart´ın, J. M. Pastor, C. Mart´ın-G´omez, D. Parisi, and I. Zuriguel, “Pedestrian collective motion in competitive room evacuation,” Scientific reports, vol. 7, no. 1, p. 10792, 2017.
J. Godoy, S. J. Guy, M. Gini, and I. Karamouzas, “C-nav: Distributed coordination in crowded multi-agent navigation,” Robotics and Autonomous Systems, p. 103631, 2020.
J. Rodr´ıguez, J. Godoy, and F. Gutierrez, “Multi-agent communication models for cooperative navigation in complex environments,” IEEE Latin America Transactions, vol. 19, no. 9, pp. 1556–1563, 2021.
J. Godoy, T. Chen, S. J. Guy, I. Karamouzas, and M. Gini, “ALAN: adaptive learning for multi-agent navigation,” Autonomous Robots, vol. 42, no. 8, pp. 1543–1562, 2018.
J. Funge, X. Tu, and D. Terzopoulos, “Cognitive modeling: knowledge, reasoning and planning for intelligent characters,” in 26th Annual Conference on Computer Graphics and Interactive Techniques, 1999, pp. 29–38.
S. J. Guy, S. Kim, M. C. Lin, and D. Manocha, “Simulating heterogeneous crowd behaviors using personality trait theory,” in Proceedings of the 2011 ACM SIGGRAPH/Eurographics symposium on computer animation, 2011, pp. 43–52.
M. A. Ramos, V. Munoz, E. Castellanos, and F. Ramos, “Modeling workplace evacuation behaviors using intelligent agents,” IEEE Latin America Transactions, vol. 14, no. 9, pp. 4150–4155, 2016.
P. Fiorini and Z. Shiller, “Motion planning in dynamic environments using Velocity Obstacles,” The Int. J. of Robotics Research, vol. 17, pp. 760–772, 1998.
J. van den Berg, S. J. Guy, M. Lin, and D. Manocha, “Reciprocal nbody collision avoidance,” in Proc. International Symposium of Robotics Research. Springer, 2011, pp. 3–19.
S. J. Guy, J. Chhugani, S. Curtis, P. Dubey, M. C. Lin, and D. Manocha, “Pledestrians: A least-effort approach to crowd simulation.” in Symposium on computer animation, 2010, pp. 119–128.
S. Juniastuti, M. Fachri, S. M. S. Nugroho, and M. Hariadi, “Crowd navigation using leader-follower algorithm based reciprocal velocity obstacles,” in 2016 International Symposium on Electronics and Smart Devices (ISESD). IEEE, 2016, pp. 148–152.
F. Muhammad, S. Juniastuti, S. M. S. Nugroho, and M. Hariadi, “Crowds evacuation simulation on heterogeneous agent using agent based reciprocal velocity obstacle,” in 2018 International Seminar on
Intelligent Technology and Its Applications (ISITIA). IEEE, 2018, pp. 275–280.
D. Hennes, D. Claes, W. Meeussen, and K. Tuyls, “Multi-robot collision avoidance with localization uncertainty,” in Autonomous Agents and MultiAgent Systems, 2012, pp. 147–154.
J. Alonso-Mora, A. Breitenmoser, M. Rufli, P. Beardsley, and R. Siegwart, “Optimal reciprocal collision avoidance for multiple nonholonomic robots,” in Distributed Autonomous Robotic Systems. Springer, 2013, pp. 203–216.
A. Bojeri and G. Iacca, “Evolutionary optimization of drone trajectories based on optimal reciprocal collision avoidance,” in 2020 27th Conference of Open Innovations Association (FRUCT). IEEE, 2020, pp.
–26.
S. Curtis, S. Guy, B. Zafar, and D. Manocha, “Virtual Tawaf: A case study in simulating the behavior of dense, heterogeneous crowds,” in 2011 IEEE International Conference on Computer Vision Workshops, ICCV Workshops 2011, Dec. 2011, pp. 128–135.
H. Lehnert, M. Araya, R. Carrasco-Davis, and M.-J. Escobar, “Bioinspired deep reinforcement learning for autonomous navigation of artificial agents,” IEEE Latin America Transactions, vol. 17, no. 12,
pp. 2037–2044, 2019.
W. Uther and M. Veloso, “Adversarial reinforcement learning,” Technical report, Carnegie Mellon University, 1997. Unpublished, Tech. Rep., 1997.
J. Kober, J. A. Bagnell, and J. Peters, “Reinforcement learning in robotics: A survey,” The International Journal of Robotics Research, vol. 32, no. 11, pp. 1238–1274, 2013.
H. Robbins, “Some aspects of the sequential design of experiments,” Bulletin of the American Mathematical Society, vol. 58, no. 5, pp. 527– 535, 1952.
J.-Y. Audibert, R. Munos, and C. Szepesv´ari, “Exploration–exploitation tradeoff using variance estimates in multi-armed bandits,” Theoretical Computer Science, vol. 410, no. 19, pp. 1876–1902, 2009.
W. G. Macready and D. H. Wolpert, “Bandit problems and the exploration/ exploitation tradeoff,” IEEE Trans. Evol. Comput., vol. 2, no. 1, pp. 2–22, 1998.
R. S. Sutton and A. G. Barto, Reinforcement Learning: An Introduction. MIT Press, 1998