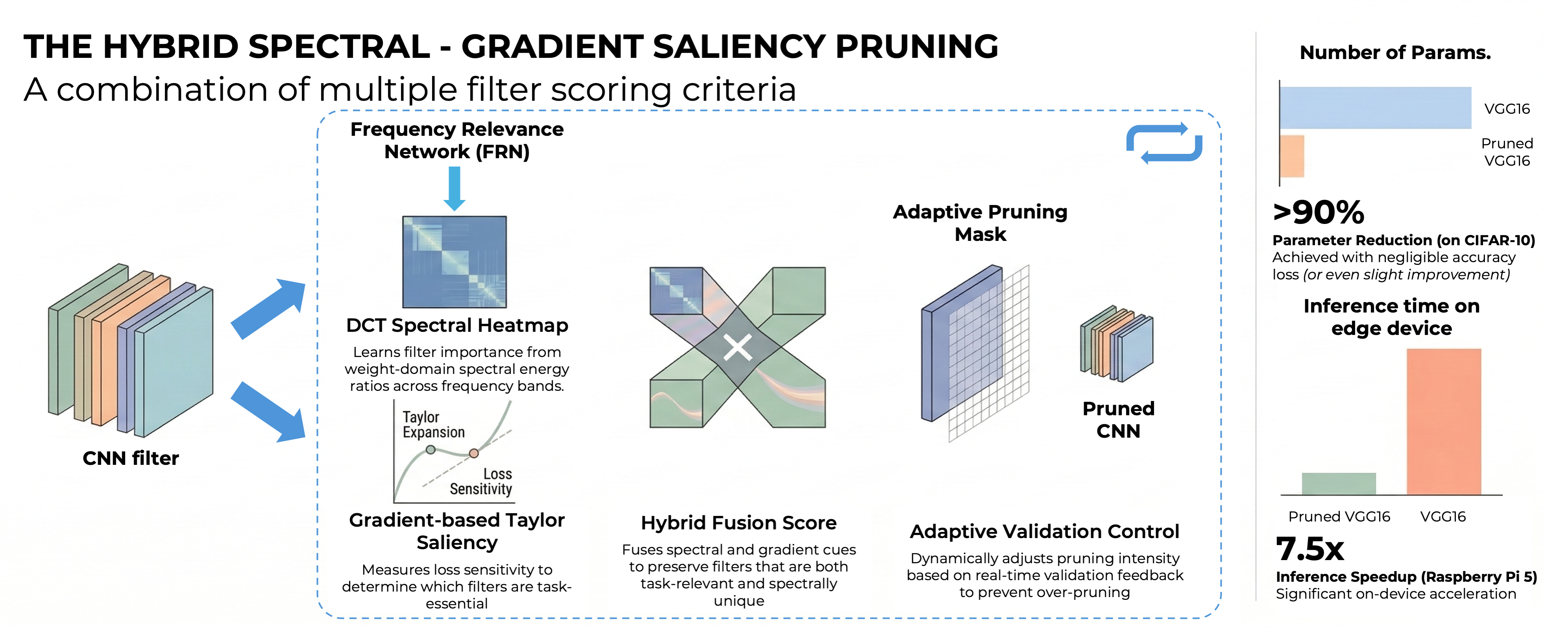
The Hybrid Spectral - Gradient Saliency Pruning: A combination of multiple filter scoring criteria
Keywords:
CNN compression, structured pruning, frequency domain, model optimizationAbstract
Deep convolutional neural networks (CNNs) have achieved remarkable performance in visual recognition but remain computationally expensive for deployment on embedded or edge devices. This paper introduces Hybrid Spectral–Gradient Saliency Pruning (HSGSP), a structured pruning framework that unifies spectral analysis and data-driven gradient saliency to achieve efficient CNN compression. The proposed method incorporates a lightweight Frequency Relevance Network (FRN) that learns to estimate the spectral importance of convolutional filters through frequency-band energy ratios, enabling fast, task-driven scoring. A hybrid saliency metric fuses the FRN’s spectral relevance with gradient-based Taylor sensitivity, ensuring filters are preserved only when important both spectrally and task-wise. An adaptive iterative schedule dynamically adjusts pruning intensity based on validation feedback, preventing over-pruning and maintaining stability. Experiments on CIFAR-10 and CIFAR-100 using VGG-16BN demonstrate up to 90% parameter reduction with negligible accuracy loss, outperforming recent structured pruning methods. Furthermore, on a Raspberry Pi 5, our pruned model delivers a 3.4x inference speedup while slightly improving accuracy, and when permitting only a 1% accuracy trade-off, the speedup increases dramatically to 7.5x. The results confirm that combining spectral cues with gradient saliency offers a robust and interpretable path toward efficient CNN deployment. The official implementation code of our method is available at https://github.com/locth/HSGSP.git.
Downloads
References
Y. He et al., “Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 4340–4349, doi: 10.1109/CVPR.2019.00447.
M. Lin et al., “HRank: Filter Pruning Using High-Rank Feature Map,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2020, pp. 1529–1538, doi: 10.1109/CVPR42600.2020.00160.
X. Ding et al., “ResRep: Lossless CNN Pruning via Decoupling Remembering and Forgetting,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Oct. 2021, pp. 4510–4520, doi: 10.1109/ICCV48922.2021.00447.
Y. Chen et al., “Discrete cosine transform for filter pruning,” Applied Intelligence, vol. 53, no. 3, pp. 3398–3414, 2023, doi: 10.1007/s10489-022-03604-2.
S. Zhang et al., “Filter pruning with uniqueness mechanism in the frequency domain for efficient neural networks,” Neurocomputing, vol. 530, pp. 116–124, 2023, doi: 10.1016/j.neucom.2023.02.004.
Y. He et al., “Soft Filter Pruning for Accelerating Deep Convolutional Neural Networks,” arXiv:1808.06866, 2018, doi: 10.24963/ijcai.2018/309.
S. Lin et al., “Towards Optimal Structured CNN Pruning via Generative Adversarial Learning,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 2790–2799, doi: 10.1109/CVPR.2019.00290.
Y. Tang et al., “SCOP: Scientific Control for Reliable Neural Network Pruning,” in Advances in Neural Information Processing Systems (NeurIPS), 2020, doi: 10.48550/arXiv.2010.10732.
Y. Wang et al., “Pruning from Scratch,” in Proc. AAAI Conf. Artificial Intelligence, vol. 34, 2020, pp. 12273–12280, doi: 10.1609/aaai.v34i07.6910.
S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,” arXiv:1510.00149, 2015, doi: 10.48550/arXiv.1510.00149.
Y. Zhang et al., “Plug-and-play: An efficient post-training pruning method for large language models,” in The Twelfth International Conference on Learning Representations (ICLR), 2024, doi: 10.20944/preprints202310.1487.v2.
E. Frantar and D. Alistarh, “Optimal brain compression: A framework for accurate post-training quantization and pruning,” in Advances in Neural Information Processing Systems, vol. 35, 2022, pp. 4475–4488, doi: 10.48550/arXiv.2208.11580.
W. Kwon et al., “A fast post-training pruning framework for transformers,” in Advances in Neural Information Processing Systems, vol. 35, 2022, pp. 24101–24116, doi: 10.48550/arXiv.2204.09656.
Y. Li et al., “BRECQ: Pushing the limit of post-training quantization by block reconstruction,” arXiv:2102.05426, 2021, doi: 10.48550/arXiv.2102.05426.
G. Xiao et al., “SmoothQuant: Accurate and efficient post-training quantization for large language models,” in Proc. Int. Conf. Machine Learning (ICML), PMLR, 2023, pp. 38087–38099.
Z. Liu et al., “Frequency-domain dynamic pruning for convolutional neural networks,” in Advances in Neural Information Processing Systems, vol. 31, 2018.
S. Khaki and W. Luo, “CFDP: Common Frequency Domain Pruning,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), 2023, pp. 4715–4724, doi: 10.1109/CVPRW59228.2023.00499.
T. Dettmers and L. Zettlemoyer, “Sparse networks from scratch: Faster training without losing performance,” arXiv:1907.04840, 2019, doi: 10.48550/arXiv.1907.04840.
A. I. Nowak et al., “Sparser, Better, Deeper, Stronger: Improving Sparse Training with Exact Orthogonal Initialization,” arXiv:2406.01755, 2024, doi: 10.48550/arXiv.2406.01755.
D. C. Mocanu et al., “Sparse training theory for scalable and efficient agents,” arXiv:2103.01636, 2021, doi: 10.48550/arXiv.2103.01636.
S. Liu et al., “Efficient and effective training of sparse recurrent neural networks,” Neural Computing and Applications, vol. 33, pp. 9625–9636, 2021, doi: 10.1007/s00521-021-05727-y.
S. Liu et al., “Don’t be so dense: Sparse-to-sparse gan training without sacrificing performance,” International Journal of Computer Vision, vol. 131, no. 10, pp. 2635–2648, 2023, doi: 10.1007/s11263-023-01824-8.
S. Liu et al., “The unreasonable effectiveness of random pruning: Return of the most naive baseline for sparse training,” arXiv:2202.02643, 2022, doi: 10.48550/arXiv.2202.02643.
Q. Sun, S. Cao, and Z. Chen, “Filter pruning via automatic pruning rate search,” in Proc. Asian Conf. Comput. Vis. (ACCV), 2022, pp. 4293–4309, doi: 10.1007/978-3-031-26351-4_36.
M. Zhao et al., “A novel deep-learning model compression based on filter-stripe group pruning and its IoT application,” Sensors, vol. 22, no. 15, p. 5623, 2022, doi: 10.3390/s22155623.
X. Sun and H. Shi, “Towards better structured pruning saliency by reorganizing convolution,” in Proc. IEEE/CVF Winter Conf. Applications of Computer Vision (WACV), 2024, pp. 2204–2214, doi: 10.1109/WACV57701.2024.00220.
C. I. Lopez-González et al., “Filter pruning for convolutional neural networks in semantic image segmentation,” Neural Networks, vol. 169, pp. 713–732, 2024, doi: 10.1016/j.neunet.2023.11.010.
B. D. Milton et al., “Adaptive CNN filter pruning using global importance metric,” Computer Vision and Image Understanding, vol. 222, p. 103511, 2022, doi: 10.1016/j.cviu.2022.103511.
K. Do et al., “Momentum adversarial distillation: Handling large distribution shifts in data-free knowledge distillation,” in Advances in Neural Information Processing Systems, vol. 35, 2022, pp. 10055–10067.