Detecting Obstetric Violence Tweets from Mexico: Annotation Guidelines and Classification with LLMs
Keywords:
Obstetric violence, manual annotation, tweets, BERTopic, LLMAbstract
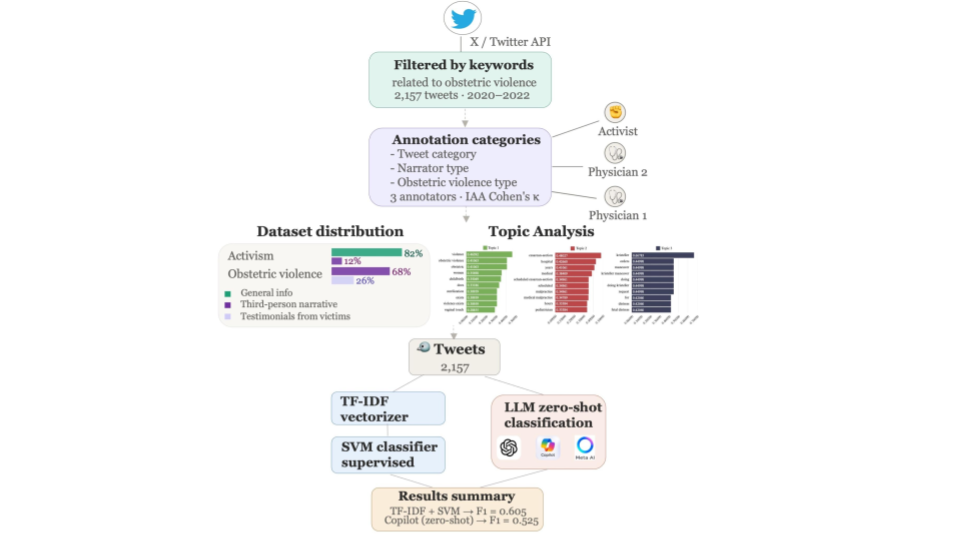
This paper presents the construction and analysis of a manually annotated corpus of tweets related to Obstetric Violence (OV) shared on Twitter (now X). The study aims to identify different types of violence experienced by women during the perinatal period, as well as activism efforts that seek to raise awareness about OV. The methodology includes data collection through keyword filtering, manual annotation guided by typologies of OV, and a descriptive analysis using BERTopic to identify themes in the data. The tweets were classified into categories such as OV, Non-OV, and Activism, and further annotated based on narrator type and type of OV violence. The study also evaluates the performance of large language models (LLMs) — including ChatGPT, Copilot, and Meta’s LLaMA — for zero-shot classification of tweets, highlighting their limitations in accurately identifying nuanced cases of OV. The research contributes a labeled dataset, a detailed annotation guide, and insights into the challenges of detecting OV in social media texts. It underscores the importance of addressing the invisibility and normalization of OV in both healthcare and NLP research.
Downloads
References
K.Crenshaw,“Mappingthemargins: Intersectionality, identitypolitics, andviolenceagainstwomenof color,”StanfordLawReview, vol. 43,
no.6,pp.1241–1299,1991,DOI:10.2307/1229039.
I. Soldevilla and N. Flores, “Natural language processing through bert for identifyinggender-basedviolencemessagesonsocialmedia,”
in2021 IEEE International Conference on InformationCommunication and SoftwareEngineering (ICICSE), 2021, pp. 204–208,DOI:
1109/ICICSE52190.2021.9404127
R. Castro and S. M. Fr´ ıas, Violencia obst´etrica y ciencias sociales : estudios cr´ıticos en Am´erica Latina. UNAM, 2022, DOI: 10.22201/crim.9786073058698p.2022.
L. I. D´ ıaz Garc´ ıa and Y. Fern´andez M., “Situaci´on legislativa de la violencia obst´etrica en am´erica latina: el caso de venezuela, ar
gentina, m´exico y chile,” Revista de derecho e la Pontificia Universidad Cat´olica de Valpara´ıso, pp. 123– 143, 12 2018, DOI: 10.4067/S0718
E. Jojoa-Tobar, Y. D. Cuchumbe-S´anchez, J. B. Ledesma-Rengifo, M. C. Mu˜noz-Mosquera, J. P. Suarez Bravo, and A. M. Paja Campo, “Violencia obst´etrica: haciendo visible lo invisible,” Salud UIS, vol. 51, no. 2, p. 136–147, abr. 2019, DOI: 10.18273/revsal.v51n2-2019006.
C. T. Beck and S. Watson, “Impact of birth trauma on breast-feeding: a tale of two pathways,” Nursing research, pp. 228–236, July-August 2008, DOI: 10.1097/01.NNR.0000313494.87282.90.
C. Bellamy and R. Castro, “Formas de violencia institucional en la sala de espera de urgencias en un hospital p´ublico de m´exico,” Revista Ciencias de la Salud, vol. 17, no. 1, p. 120–137, february 2019, DOI: 10.12804/revistas.urosario.edu.co/revsalud/a.7621.
H. Gomez-Adorno, G. Bel-Enguix, G. Sierra, J. Barajas, and W. ´ Alvarez, “Machine learning and deep learning sentiment analysis models: Case study on the sent-covid corpus of tweets in mexican spanish,” Informatics, vol. 11, 2024, DOI: 10.3390/informatics11020024.
C. Roberto, “G´enesis y pr´actica del habitus m´edico autoritario en m´exico,” Revista Mexicana de Sociolog´ıa, vol. 76, no. 2, pp. 167–197,
May 2014, DOI: 10.22201/iis.01882503p.2014.2.46428.
R. Egger, “Topic modelling,” Tourism on the Verge, vol. Part F1051, pp. 375–403, 2022, DOI: 10.1007/978-3-030-88389-8 18.
A. Abdelrazek, Y. Eid, E. Gawish, W. Medhat, and A. Hassan, “Topic modeling algorithms and applications: A survey,” Information Systems, vol. 112, p. 102131, 2 2023, DOI: 10.1016/J.IS.2022.102131.
S. P. Crain, K. Zhou, S.-H. Yang, and H. Zha, Dimensionality Reduction and Topic Modeling: From Latent Semantic Indexing to Latent Dirichlet Allocation and Beyond. Springer US, 2012, pp. 129–161, DOI: 10.1007/978-1-4614-3223-4 5.
J. Devlin, M. W. Chang, K. Lee, and K. Toutanova, “Bert: Pretraining of deep bidirectional transformers for language understanding,”
NAACL HLT 2019- 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language
Technologies- Proceedings of the Conference, vol. 1, pp. 4171–4186, 10 2018, DOI: 10.48550/arXiv.1810.04805.
M. Grootendorst, “Bertopic: Neural topic modeling with a class-based tf-idf procedure,” 3 2022, DOI: 10.48550/arXiv.2203.05794.
J. M. P´erez, M. Rajngewerc, J. C. Giudici, D. A. Furman, F. Luque, L. A. Alemany, and M. V. Mart´ ınez, “pysentimiento: A python
toolkit for opinion mining and social nlp tasks,” 2024, DOI: 10.48550/arXiv.2106.09462.
Z. O. Merhi and A. O. Awonuga, “The role of uterine fundal pressure in the management of the second stage of labor: a reappraisal,”
Obstetrical & gynecological survey, vol. 60, pp. 599–603, 9 2005, DOI: 10.1097/01.OGX.0000175804.68946.AC. [Online]. Available:
https://pubmed.ncbi.nlm.nih.gov/16121114/
G. Acmaz, E. Albayrak, G. Oner, M. Baser, G. Aykut, G. Tekin, G. Zararsiz, and I. Muderris, “The effect of kristeller maneu
ver on maternal and neonatal outcome,” Archives of Clinical and Experimental Surgery (ACES), vol. 4, p. 29, 2015, DOI:
5455/ACES.20140328024258.
“Fundal pressure in the second stage of labor: time to face the invisible enemy,” The Journal of Maternal-Fetal & Neonatal Medicine, vol. 34, no. 18, p. 3094–3095, 2019, DOI: 10.1080/14767058.2019.1677600.
S. Tongate and J. D. Gibbs, “Nurses, physicians and disagreements about fundal pressure: how we used evidence to change practice,” Nursing for women’s health, vol. 14, pp. 137–142, 2010, DOI: 10.1111/j.1751
X.2010.01527.x. [Online]. Available: https://pubmed.ncbi.nlm.nih.
gov/20409137/
A. Malvasi, S. Zaami, A. Tinelli, G. Trojano, G. Montanari-Vergallo, and E. Marinelli, “Kristeller maneuvers or fundal pressure and maternal/neonatal morbidity: obstetric and judicial literature review.” Matern Fetal Neonatal Med., vol. 32, no. 15, pp. 2598–2607, august 2019, DOI: 10.1080/14767058.2018.1441278.
Y. Zhang, M. Wang, C. Ren, Q. Li, P. Tiwari, B. Wang, and J. Qin, “Pushing the limits of llm capacity for text classification,” arXiv, 2024,
DOI: 10.48550/arXiv.2402.07470.
P. Lepagnol, T. Gerald, S. Ghannay, C. Servan, and S. Rosset, “Small language models are good too: An empirical study of zero-shot classification,” arXiv, 2024, DOI: 10.48550/arXiv.2404.11122
T. Hu and X.-H. Zhou, “Unveiling llm evaluation focused on metrics: Challenges and solutions,” arXiv, 2024, DOI:
48550/arXiv.2404.09135.