A Comparative Analysis of the Smith-Waterman Algorithm on Raspberry Pi-Based Parallel Platforms
Keywords:
High-Performance Computing, Parallel Computing, Smith-Waterman, Raspberry Pi, Sequence AlignmentAbstract
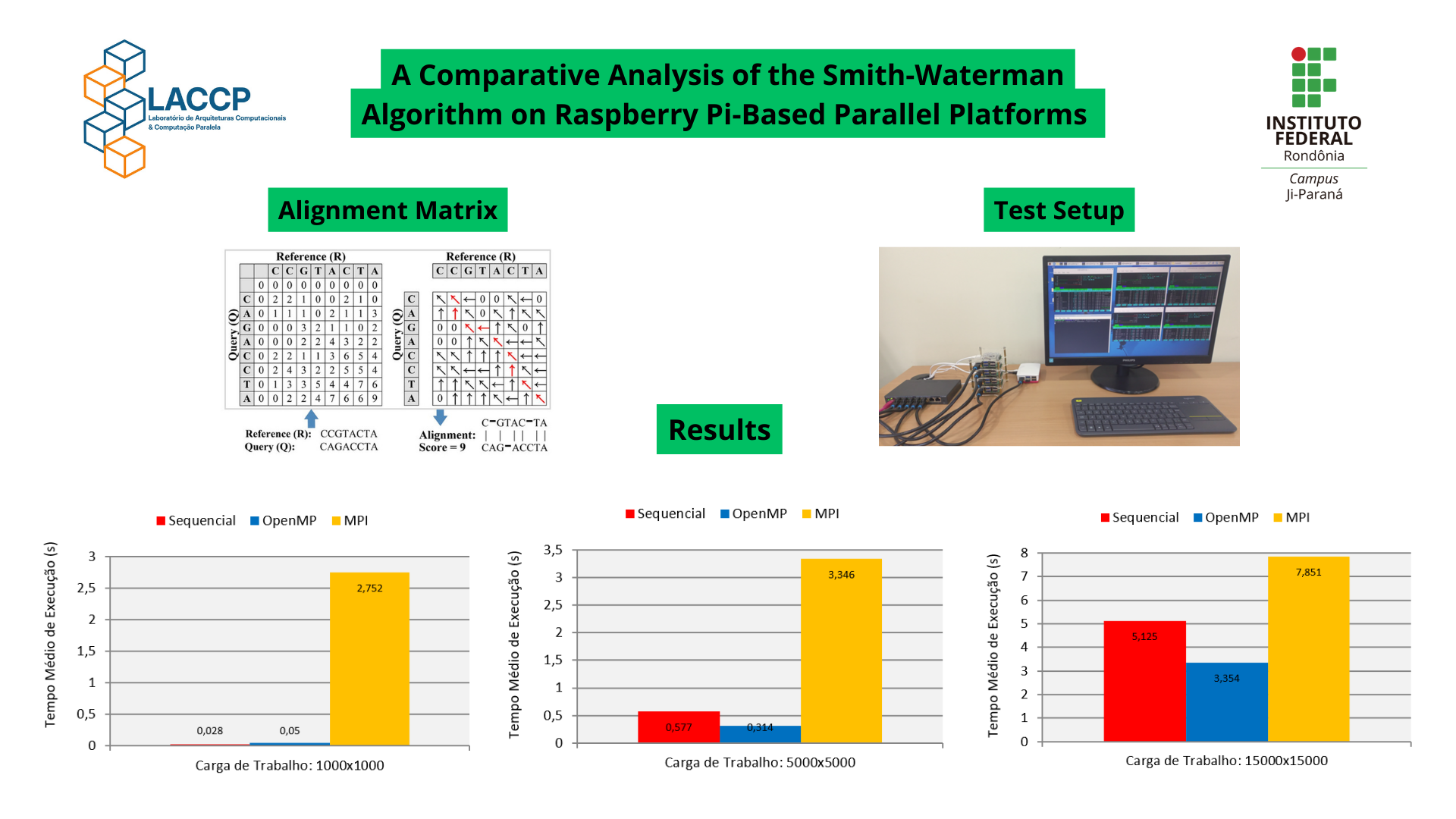
O alinhamento de sequências é uma tarefa fundamental em bioinformática, exigindo processamento computacional intensivo que cresce quadraticamente com o tamanho da sequência. A Computação de Alto Desempenho (HPC) oferece soluções essenciais para acelerar tais tarefas. Este artigo apresenta uma análise detalhada do desempenho do algoritmo Smith-Waterman de alinhamento local, comparando uma implementação sequencial em C com versões paralelas projetadas para arquiteturas modernas de cluster e multi-core. Para paralelismo de memória compartilhada, uma versão OpenMP foi desenvolvida usando uma estratégia de frente de onda para gerenciar dependências de dados; para memória distribuída, uma versão MPI foi implementada usando uma decomposição de domínio baseada em linhas 2D. A avaliação foi conduzida em uma plataforma de baixo custo composta por um único nó Raspberry Pi 5 e um cluster de cinco nós (ClusterPi-5), usando tamanhos de sequência de 1000, 5000 e 15000 como cargas de trabalho. Os resultados demonstram um claro trade-off entre computação e sobrecarga. A implementação do OpenMP apresentou degradação de desempenho na menor carga de trabalho, com um aumento de velocidade de apenas 0,56x, mas obteve ganhos significativos de desempenho para problemas maiores, com um pico de aumento de velocidade de 1,84x para sequências de 5.000 bases. Em contraste, a implementação do MPI apresentou desempenho consistentemente inferior, provando ser menos eficiente do que a versão sequencial em todas as configurações testadas devido à alta sobrecarga de comunicação. A análise conclui que, para o algoritmo Smith-Waterman nesta plataforma HPC acessível, o modelo OpenMP de memória compartilhada é uma estratégia de aceleração eficaz para problemas suficientemente grandes, enquanto o modelo MPI de memória distribuída, em sua implementação atual, é compensado por seus custos de comunicação. Isso ressalta que a escolha de um modelo paralelo deve equilibrar cuidadosamente os paradigmas arquitetônicos com as características algorítmicas para alcançar melhorias significativas de desempenho.
Downloads
References
W. P. Petersen and P. Arbenz, Introduction to Parallel Computing: A Practical Guide with Examples in C. New York, EUA: Oxford University Press, 1st edition, 2004, isbn: 978-0-19-851576-0, doi: https://doi.org/10.1093/oso/9780198515760.002.0001.
C. Xavier, R. Sachetto, V. Vieira, R. W. Santos, and W. Meira Jr., “Multi level Parallelism in the Computational Modeling of the Heart,” in Proceedings of the 19th International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD), Gramado, RS, Brazil, 2007, pp. 3-10, doi: https://doi.org/10.1109/SBAC-PAD.2007.19.
T. F. Smith and M. S. Waterman, “Identification of Common Molecular Subsequences,” Journal of Molecular Biology, vol. 147, no. 1, pp. 195-197, 1981, doi: https://doi.org/10.1016/0022-2836(81)90087-5.
TOP500.org, “Top 500 Supercomputing Site,” 2025. [Online]. Available: https://top500.org/.
OpenMP Architecture Review Board, “The OpenMP API Specification for Parallel Programming,” 2025. [Online]. Available: http://openmp.org/.
MPI Forum, “MPI: A Message-Passing Interface Standard, Version 4.1,” 2025. [Online]. Available: https://www.mpi-forum.org/docs/.
F. A. Lima, W. R. A. Dias, and E. D. Moreno, “Implementação de um Cluster Embarcado usando a Plataforma Raspberry Pi,” in Escola Regional de Alto Desempenho do Rio de Janeiro (ERAD-RJ), Nova Iguaçu, RJ, Brasil, 2020, pp. 11-15, doi: https://doi.org/10.5753/eradrj.2020.14509.
A. L. J. Ignácio and W. R. A. Dias, “Análise do Desempenho Computacional de Algoritmos Paralelizados com OpenMP e MPI Executados em Raspberry Pi,” in Workshop de Iniciação Científica - Simpósio em Sistemas Computacionais de Alto Desempenho (SSCAD), Porto Alegre, RS, Brasil, 2023, pp. 41-48, doi: https://doi.org/10.5753/wscad_estendido.2023.235967.
G. O. Ribeiro, L. F. Sêmeler, and W. R. A. Dias, “Avaliação de Desempenho dos Algoritmos de Números Primos e Monte Carlo em Ambientes HPC,” in Workshop de Iniciação Científica - Simpósio em Sistemas Computacionais de Alto Desempenho (SSCAD), São Carlos, SP, Brasil, 2024, pp. 65-72, doi: https://doi.org/10.5753/sscad_estendido.2024.244768.
L. F. T. Silva and W. R. A. Dias, “Avaliação de Algoritmos de Ordenação de Dados em Ambiente de HPC com Raspberry Pi,” in Workshop de Iniciação Científica - Simpósio em Sistemas Computacionais de Alto Desempenho (SSCAD), Bonito, MS, Brasil, 2025, pp. 57-64, doi: https://doi.org/10.5753/sscad_estendido.2025.15942.
B. Chapman, G. Jost, and R. van der Pas, Using OpenMP: Portable Shared Memory Parallel Programming. Cambridge, MA, USA: MIT Press, 1st edition, 2007, isbn: 978-0-26-253302-7, doi: https://doi.org/10.5860/choice.46-0930.
C. Xavier, R. Sachetto, V. Vieira, R. W. Santos, and W. Meira Jr., “Multi level Parallelism in the Computational Modeling of the Heart,” in Proceedings of the 19th International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD),
Gramado, RS, Brazil, 2007, pp. 3-10, doi: https://doi.org/10.1109/SBAC-PAD.2007.19.
P. S. Pacheco and M. Malensek, An Introduction to Parallel Programming. Morgan Kaufmann, 2nd edition, 2021, isbn: 978-0-12-804605-0, doi: https://doi.org/10.1016/C2015-0-01650-1.
R. Trobec, B. Slivnik, P. Bulić, and B. Robič, Introduction to Parallel Computing: From Algorithms to Programming on State-of-the-Art Platforms. Springer, 1st edition, 2018, isbn: 978-3-319-98833-7, doi: https://doi.org/10.1007/978-3-319-98833-7.
S. Beretta, “Algorithms for Strings and Sequences: Pairwise Alignment,” Encyclopedia of Bioinformatics and Computational Biology, vol. 1, no. 1, pp. 22-29, 2019, doi: https://doi.org/10.1016/B978-0-12-809633-8.20317-8.
Z. Xia, Y. Cui, A. Zhang, T. Tang, L. Peng, C. Huang, C. Yang, and X. Liao, “A Review of Parallel Implementations for the Smith–Waterman Algorithm,” Interdisciplinary Sciences: Computational Life Sciences, vol. 14, no. 1, pp. 1-14, 2021, doi: https://doi.org/10.1007/s12539-021-00473-0.
A. Dhar, I. Chauhan, H. K. Azad, A. Bamzai, and T. Yadav, “Parallelization of the Smith-Waterman Algorithm to Accelerate DNA Sequence Alignment,” in 3rd International Conference on Artificial Intelligence For Internet of Things (AIIoT), Vellore, India, 2024, pp. 887-892, doi: https://doi.org/10.1109/AIIoT58432.2024.10574609.
K. Ninama, J. Patel, K. K. Girish; M. R. V. S. R. S. Reddy, and B. Bhowmik, “Performance Analysis of Hybrid MPI and OpenMP on Smith-Waterman Algorithm,” in 3rd International Conference on Intelligent Systems, Advanced Computing and Communication (ISACC), Silchar, India, 2025, pp. 887-892, doi: https://doi.org/10.1109/ISACC65211.2025.10969164.
H. Khaled, H. M. Faheem, M. Fayez, I. Katib, and N. R. Aljohani, “Performance Improvement of the Parallel Smith Waterman Algorithm Implementation using Hybrid MPI-OpenMP Model,” in SAI Computing Conference (SAI), London, United Kingdom, 2016, pp. 1232-1234, doi: https://doi.org/10.1109/SAI.2016.7556136.
F. A. Lima, E. D. Moreno, and W. R. A. Dias, “Performance Analysis of a Low Cost Cluster with Parallel Applications and ARM Processors,” IEEE Latin America Transactions, vol. 14, no. 11, pp. 4591-4596, 2016, doi: https://doi.org/10.1109/TLA.2016.7795834.