Learnable Query Contrast and Spatio-temporal Prediction on Point Cloud Video Pre-training
Keywords:
3D deep learning, point clouds, self-supervised pre-training, contrastive learningAbstract
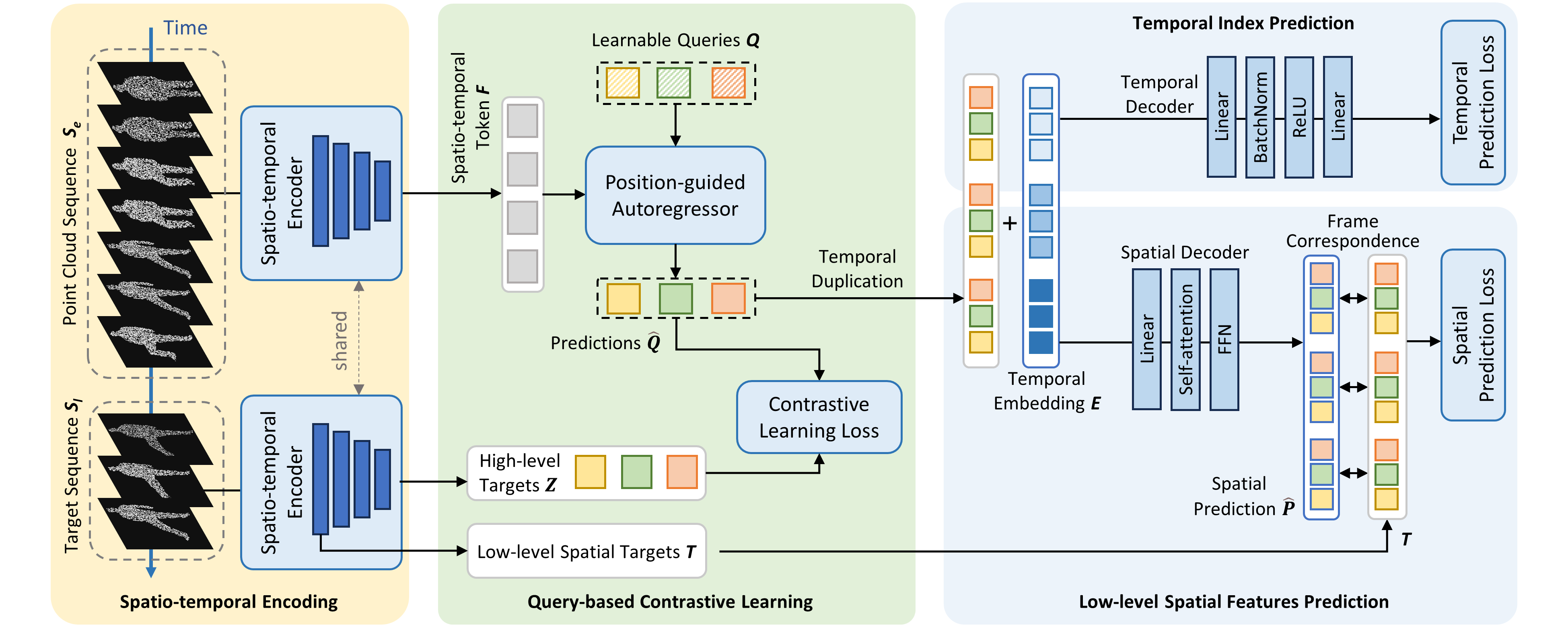
Point cloud videos capture the time-varying environment and are widely used for dynamic scene understanding. Existing methods develop effective networks for point cloud videos but do not fully utilize the prior information uncovered during pre-training. Furthermore, relying on a single supervised task with a large amount of manually labeled data may be insufficient to capture the foundational structures in point cloud videos. In this paper, we propose a pre-training framework Query-CP to learn the representations of point cloud videos through multiple self-supervised pretext tasks. First, tokenlevel contrast is developed to predict future features under the guidance of historical information. Using a position-guided autoregressor with learnable queries, the predictions are directly contrasted with corresponding targets in the high-level feature space to capture fine-grained semantics. Second, performing only contrastive learning fails to fully explore the complementary structures and dynamics information. To alleviate this, a decoupled spatio-temporal prediction task is designed, where we use a spatial branch to predict low-level features and a temporal branch to predict timestamps of the target sequence explicitly. By combining the above self-supervised tasks, multi-level information is captured during the pre-training stage. Finally, the encoder is fine-tuned and evaluated for action recognition and dynamic semantic segmentation on three datasets. The results demonstrate the effectiveness of our Query-CP. Especially, compared with the state-of-the-art methods, the fine-tuning accuracy on action recognition improves by 3.23% for 24-frame point cloud videos, and the mean accuracy increases by 4.21%.
Downloads
References
Q. Hu, B. Yang, L. Xie, S. Rosa, Y. Guo, Z. Wang, N. Trigoni, and A. Markham, “RandLA-Net: Efficient semantic segmentation of large-scale point clouds,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 108–11 117, doi:10.1109/CVPR42600.2020.01112.
Y. Guo, H. Wang, Q. Hu, H. Liu, L. Liu, and M. Bennamoun, “Deep learning for 3D point clouds: A survey,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 12, pp. 4338–4364, 2020, doi:10.1109/TPAMI.2020.3005434.
H. Fan, X. Yu, Y. Ding, Y. Yang, and M. Kankanhalli, “PSTNet: Point spatio-temporal convolution on point cloud sequences,” arXiv preprint arXiv:2205.13713, 2022, doi:10.48550/arXiv.2205.13713.
H. Fan, X. Yu, Y. Yang, and M. Kankanhalli, “Deep hierarchical representation of point cloud videos via spatio-temporal decomposition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 12, pp. 9918–9930, 2021, doi:10.1109/TPAMI.2021.3135117.
H. Fan, Y. Yang, and M. Kankanhalli, “Point 4D transformer networks for spatio-temporal modeling in point cloud videos,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 14 204–14 213, doi:10.1109/CVPR46437.2021.01398.
Y. Wei, H. Liu, T. Xie, Q. Ke, and Y. Guo, “Spatial-temporal transformer for 3D point cloud sequences,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022, pp. 1171–1180, doi:10.1109/WACV51458.2022.00073.
H. Fan, Y. Yang, and M. Kankanhalli, “Point spatio-temporal transformer networks for point cloud video modeling,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 2, pp. 2181–2192, 2022, doi:10.1109/TPAMI.2022.3161735.
Y. Wang, Y. Xiao, F. Xiong, W. Jiang, Z. Cao, J. T. Zhou, and J. Yuan, “3DV: 3D dynamic voxel for action recognition in depth video,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 511–520, doi:10.1109/CVPR42600.2020.00059.
X. Liu, M. Yan, and J. Bohg, “MeteorNet: Deep learning on dynamic 3D point cloud sequences,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 9245–9254, doi:10.1109/ICCV.2019.00934.
C. R. Qi, L. Yi, H. Su, and L. J. Guibas, “PointNet++: Deep hierarchical feature learning on point sets in a metric space,” Advances in Neural Information Processing Systems, pp. 5099–5108, 2017, doi:10.48550/arXiv.1706.02413.
H. Wang, L. Yang, X. Rong, J. Feng, and Y. Tian, “Self-supervised 4D spatio-temporal feature learning via order prediction of sequential point cloud clips,” in Proceedings of the IEEE Winter Conference on Applications of Computer Vision, 2021, pp. 3762–3771, doi:10.1109/WACV48630.2021.00381.
Y. Dong, Z. Zhang, Y. Liu, and L. Yi, “Complete-to-partial 4D distillation for self-supervised point cloud sequence representation learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 17 661–17 670, doi:10.1109/CVPR52729.2023.01694.
X. Sheng, Z. Shen, G. Xiao, L. Wang, Y. Guo, and H. Fan, “Point contrastive prediction with semantic clustering for self-supervised learning on point cloud videos,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 16 469–16 478, doi:10.1109/ICCV51070.2023.01514.
Z. Shen, X. Sheng, H. Fan, L. Wang, Y. Guo, Q. Liu, H. Wen, and X. Zhou, “Masked spatio-temporal structure prediction for self-supervised learning on point cloud videos,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp.16 580–16 589, doi:10.1109/ICCV51070.2023.01520.
X. Sheng, Z. Shen, and G. Xiao, “Contrastive predictive autoencoders for dynamic point cloud self-supervised learning,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2023, pp. 9802–9810, doi:10.1609/aaai.v37i8.26170.
Z. Shen, X. Sheng, L. Wang, Y. Guo, Q. Liu, and X. Zhou, “PointCMP: Contrastive mask prediction for self-supervised learning on point cloud videos,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 1212–1222, doi:10.1109/CVPR52729.2023.00123.
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-End object detection with transformers,” in Proceedings of the European conference on computer vision, 2020, pp. 213–229, doi:10.1007/978-3-030-58452-8 13.
B. Cheng, A. G. Schwing, and A. Kirillov, “Per-pixel classification is not all you need for semantic segmentation,” in Advances in Neural Information Processing Systems, 2021, pp. 17 864–17 875, doi:10.48550/arXiv.2107.06278.
J. Li, D. Li, S. Savarese, and S. Hoi, “BLIP-2: Bootstrapping languageimage pre-training with frozen image encoders and large language models,” in International conference on machine learning, 2023, pp. 19 730–19 742, doi:10.48550/arXiv.2301.12597.
W. Li, Z. Zhang, and Z. Liu, “Action recognition based on a bag of 3D points,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2010, pp. 9–14, doi:10.1109/CVPRW.2010.5543273.
A. Shahroudy, J. Liu, T.-T. Ng, and G. Wang, “NTU RGB+D: A large scale dataset for 3D human activity analysis,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2016, pp. 1010–1019, doi:10.1109/CVPR.2016.115.
C. Choy, J. Gwak, and S. Savarese, “4D spatio-temporal convnets: Minkowski convolutional neural networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 3075–3084, doi:10.1109/CVPR.2019.00319.
A. Vaswani, N. M. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems, 2017, pp. 5998– 6008, doi:10.48550/arXiv.1706.03762.
A. van den Oord, Y. Li, and O. Vinyals, “Representation learning with contrastive predictive coding,” arXiv preprint arXiv:1807.03748, 2018, 2018, doi:10.48550/arXiv.1807.03748.
J.-X. Zhong, K. Zhou, Q. Hu, B. Wang, N. Trigoni, and A. Markham, “No Pain, Big Gain: Classify dynamic point cloud sequences with static models by fitting feature-level space-time surfaces,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 8500–8510, doi:10.1109/CVPR52688.2022.00832.
H. Wen, Y. Liu, J. Huang, B. Duan, and L. Yi, “Point primitive transformer for long-term 4D point cloud video understanding,” in Proceedings of the European Conference on Computer Vision, 2022, pp. 19–35, doi:10.1007/978-3-031-19818-2 2.