Multilevel Deep Semantic Feature Asymmetric Network for Cross-Modal Hashing Retrieval
Keywords:
Cross-modal hashing, cross-modal retrieval, mul-feature method, graph convolutional networkAbstract
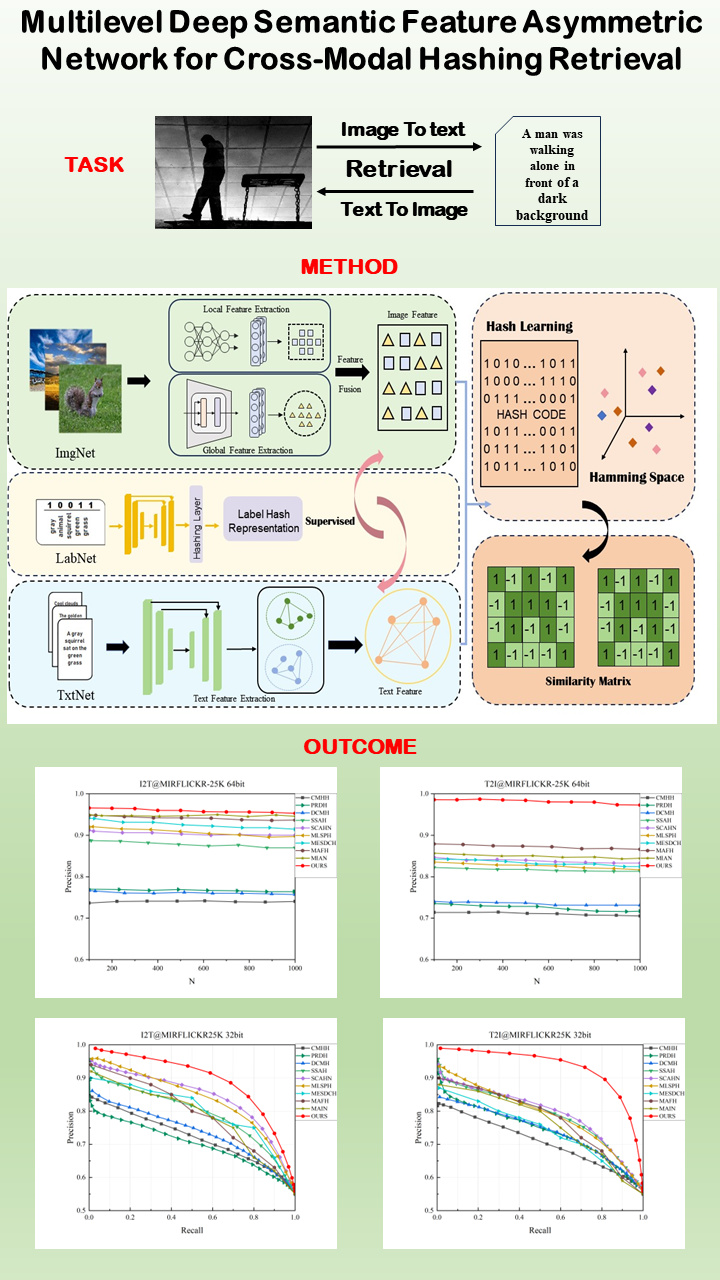
Cross-modal hash retrieval has been widely applied due to its efficiency and low storage overhead. In the domain of supervised cross-modal hash retrieval, existing methods exhibit limitations in refining data features, leading to insufficiently detailed semantic information extraction and inaccurate reflection of data similarity. The challenge lies in utilizing multi-level deep semantic features of the data to generate more refined hash representations, thereby reducing the semantic gap and heterogeneity caused by different modalities. To address this challenging problem, we propose a multilevel deep semantic feature asymmetric network structure (MDSAN). Firstly, this architecture explores the multilevel deep features of the data, generating more accurate hash representations under richer supervised information guidance. Secondly, we investigate the preservation of asymmetric similarity within and between different modalities, allowing for a more comprehensive utilization of the multilevel deep features to bridge the gap among diverse modal data. Our network architecture effectively enhances model accuracy and robustness. Extensive experiments on three datasets validate the significant improvement advantages of the MDSAN model structure compared to current methods.
Downloads
References
X. Li, J. Yu, S. Jiang, H. Lu, and Z. Li, “Msvit: training multiscale vision transformers for image retrieval,” IEEE Transactions on Multimedia, 2023. doi:10.1109/TMM.2023.3304021.
C. Deng, E. Yang, T. Liu, and D. Tao, “Two-stream deep hashing with class-specific centers for supervised image search,” IEEE transactions on neural networks and learning systems, vol. 31, no. 6, pp. 2189–2201, 2019. doi:10.1109/tip.2018.2821921.
X. Yao, D. She, S. Zhao, J. Liang, Y.-K. Lai, and J. Yang, “Attention aware polarity sensitive embedding for affective image retrieval,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1140–1150, 2019. doi:10.1109/ICCV.2019.00123.
Q.-Y. Jiang and W.-J. Li, “Discrete latent factor model for cross-modal hashing,” IEEE Transactions on Image Processing, vol. 28, no. 7, pp. 3490–3501, 2019. doi:10.1109/TIP.2019.2897944.
D. Mandal, K. N. Chaudhury, and S. Biswas, “Generalized se mantic preserving hashing for cross-modal retrieval,” IEEE Trans actions on Image Processing, vol. 28, no. 1, pp. 102–112, 2018. doi:10.1109/TIP.2018.2863040.
X. Nie, B. Wang, J. Li, F. Hao, M. Jian, and Y. Yin, “Deep multiscale fusion hashing for cross-modal retrieval,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 1, pp. 401–410, 2020. doi:10.1109/TCSVT.2020.2974877.
D. Zhang and W.-J. Li, “Large-scale supervised multimodal hashing with semantic correlation maximization,” in Proceedings of the AAAI conference on artificial intelligence, vol. 28, 2014. doi:10.1609/aaai.v28i1.8995.
J. Zhou, G. Ding, and Y. Guo, “Latent semantic sparse hashing for cross modal similarity search,” in Proceedings of the 37th international ACM SIGIR conference on Research & development in information retrieval, pp. 415–424, 2014. doi: 10.1145/2600428.2609610.
G. Ding, Y. Guo, and J. Zhou, “Collective matrix factorization hashing for multimodal data,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2075–2082, 2014. doi:10.1109/CVPR.2014.267.
Y. Guo, Y. Liu, A. Oerlemans, S. Lao, S. Wu, and M. S. Lew, “Deep learning for visual understanding: A review,” Neurocomputing, vol. 187, pp. 27–48, 2016. doi:10.1016/j.neucom.2015.09.116.
M. M. Bronstein, A. M. Bronstein, F. Michel, and N. Paragios, “Data fusion through cross-modality metric learning using similarity sensitive hashing,” in 2010 IEEE computer society conference on computer vision and pattern recognition, pp. 3594–3601, IEEE, 2010. doi:10.1109/cvpr.2010.5539928.
C. Deng, Z. Chen, X. Liu, X. Gao, and D. Tao, “Triplet-based deep hashing network for cross-modal retrieval,” IEEE Transactions on Image Processing, vol. 27, no. 8, pp. 3893–3903, 2018. doi:10.1109/tip.2018.2821921.
P.-F. Zhang, Y. Li, Z. Huang, and X.-S. Xu, “Aggregation-based graph convolutional hashing for unsupervised cross-modal retrieval,” IEEE Transactions on Multimedia, vol. 24, pp. 466–479, 2021. doi:10.1109/tmm.2021.3053766.
T. Baltrušaitis, C. Ahuja, and L.-P. Morency, “Multimodal machine learning: A survey and taxonomy,” IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 2, pp. 423–443, 2018. doi:10.1109/tpami.2018.2798607.
L. Zhu, T. Wang, F. Li, J. Li, Z. Zhang, and H. T. Shen, “Cross-modal retrieval: A systematic review of methods and future directions,” arXiv preprint arXiv:2308.14263, 2023. doi:10.1145/3539618.3594245.
D. Mandal, K. N. Chaudhury, and S. Biswas, “Generalized semantic preserving hashing for n-label cross-modal retrieval,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4076–4084, 2017. doi:10.1109/TIP.2018.2863040.
Z. Lin, G. Ding, M. Hu, and J. Wang, “Semantics-preserving hashing for cross-view retrieval,” pp. 3864–3872, 2015. doi:10.1109/cvpr.2015.7299011.
H. Liu, R. Ji, Y. Wu, and G. Hua, “Supervised matrix factorization for cross-modality hashing,” arXiv preprint arXiv:1603.05572, 2016. doi:10.48550/arXiv.1603.05572.
Q.-Y. Jiang and W.-J. Li, “Deep cross-modal hashing,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3232–3240, 2017. doi:10.1109/cvpr.2017.348.
S. Jin, S. Zhou, Y. Liu, C. Chen, X. Sun, H. Yao, and X.-S. Hua, “Ssah: Semi-supervised adversarial deep hashing with self-paced hard sample generation,” in Proceedings of the AAAI conference on artificialintelligence, vol. 34, pp. 11157–11164, 2020. doi:10.1609/aaai.v34i07.6773.
Y. Cao, B. Liu, M. Long, and J. Wang, “Cross-modal hamming hashing,” in Proceedings of the European conference on computer vision (ECCV), pp. 202–218, 2018. doi:10.1007/978-3-030-01246-5-13.
X. Zou, X. Wang, E. M. Bakker, and S. Wu, “Multi-label semantics preserving based deep cross-modal hashing,” Signal Processing: Image Communication, vol. 93, p. 116131, 2021. doi:10.1016/j.image.2020.116131.
X. Zou, S. Wu, N. Zhang, and E. M. Bakker, “Multi-label modality enhanced attention based self-supervised deep cross-modal hashing,” Knowledge-Based Systems, vol. 239, p. 107927, 2022. doi:10.1016/j.knosys.2021.107927.
S. Teng, S. Lin, L. Teng, N. Wu, Z. Zheng, L. Fei, and W. Zhang, “Joint specifics and dual-semantic hashing learning for cross-modal retrieval,” Neurocomputing, vol. 565, p. 126993, 2024. doi:10.1016/j.neucom.2023.126993.
M. Meng, J. Sun, J. Liu, J. Yu, and J. Wu, “Semantic dis entanglement adversarial hashing for cross-modal retrieval,” IEEE Transactions on Circuits and Systems for Video Technology, 2023. doi:10.1109/tcsvt.2023.3293104.
Z. Zhang, H. Luo, L. Zhu, G. Lu, and H. T. Shen, “Modality-invariant asymmetric networks for cross-modal hashing,” IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 5, pp. 5091–5104, 2022. doi:10.1109/tkde.2022.3144352.
X. Li, J. Yu, H. Lu, S. Jiang, Z. Li, and P. Yao, “Mafh: Multilabel aware framework for bit-scalable cross-modal hashing,” Knowledge-Based Systems, vol. 279, p. 110922, 2023. doi:10.1016/j.knosys.2023.110922.
Y. Chen, S. Wang, J. Lu, Z. Chen, Z. Zhang, and Z. Huang, “Local graph convolutional networks for cross-modal hashing,” in Proceedings of the 29th ACM international conference on multimedia, pp. 1921– 1928, 2021. doi:10.1145/3474085.3475346.
F. Wu, S. Li, G. Gao, Y. Ji, X.-Y. Jing, and Z. Wan, “Semi-supervised cross-modal hashing via modality-specific and cross-modal graph convolutional networks,” Pattern Recognition, vol. 136, p. 109211, 2023. doi:10.1016/j.patcog.2022.109211.
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017. doi:10.48550/arXiv.1706.03762.
S. R. Dubey, S. K. Singh, and W.-T. Chu, “Vision transformer hashing for image retrieval,” in 2022 IEEE international conference on multimedia and expo (ICME), pp. 1–6, IEEE, 2022. doi:10.1109/ICME52920.2022.9859900.
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014. doi:10.48550/arXiv.1409.1556.
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020. doi:10.48550/arXiv.2010.11929.
Y. Weiss, A. Torralba, and R. Fergus, “Spectral hashing,” Advances in neural information processing systems, vol. 21, 2008. doi:10.5555/2981780.2981999.
W. Liu, J. Wang, S. Kumar, and S.-F. Chang, “Hashing with graphs,” in Proceedings of the 28th international conference on machine learning (ICML-11), pp. 1–8, 2011. doi:10.5555/3104482.3104483.
M. M. Bronstein, A. M. Bronstein, F. Michel, and N. Paragios, “Data fusion through cross-modality metric learning using similarity sensitive hashing,” in 2010 IEEE computer society conference on computer vision and pattern recognition, pp. 3594–3601, IEEE, 2010. doi:10.1109/cvpr.2010.5539928.
E. Yang, C. Deng, W. Liu, X. Liu, D. Tao, and X. Gao, “Pairwise relationship guided deep hashing for cross-modal retrieval,” in proceedings of the AAAI Conference on Artificial Intelligence, vol. 31, 2017. doi:10.1609/aaai.v31i1.10719.
H. Cui, L. Zhu, J. Li, Y. Yang, and L. Nie, “Scalable deep hashing for large-scale social image retrieval,” IEEE Transactions on image processing, vol. 29, pp. 1271–1284, 2019. doi:10.1109/tip.2019.2940693.