Code Smell Detection Research Based on Pre-training and Stacking Models
Keywords:
Code Smell, Pre-training Model, Textual Features, Stacking ModelAbstract
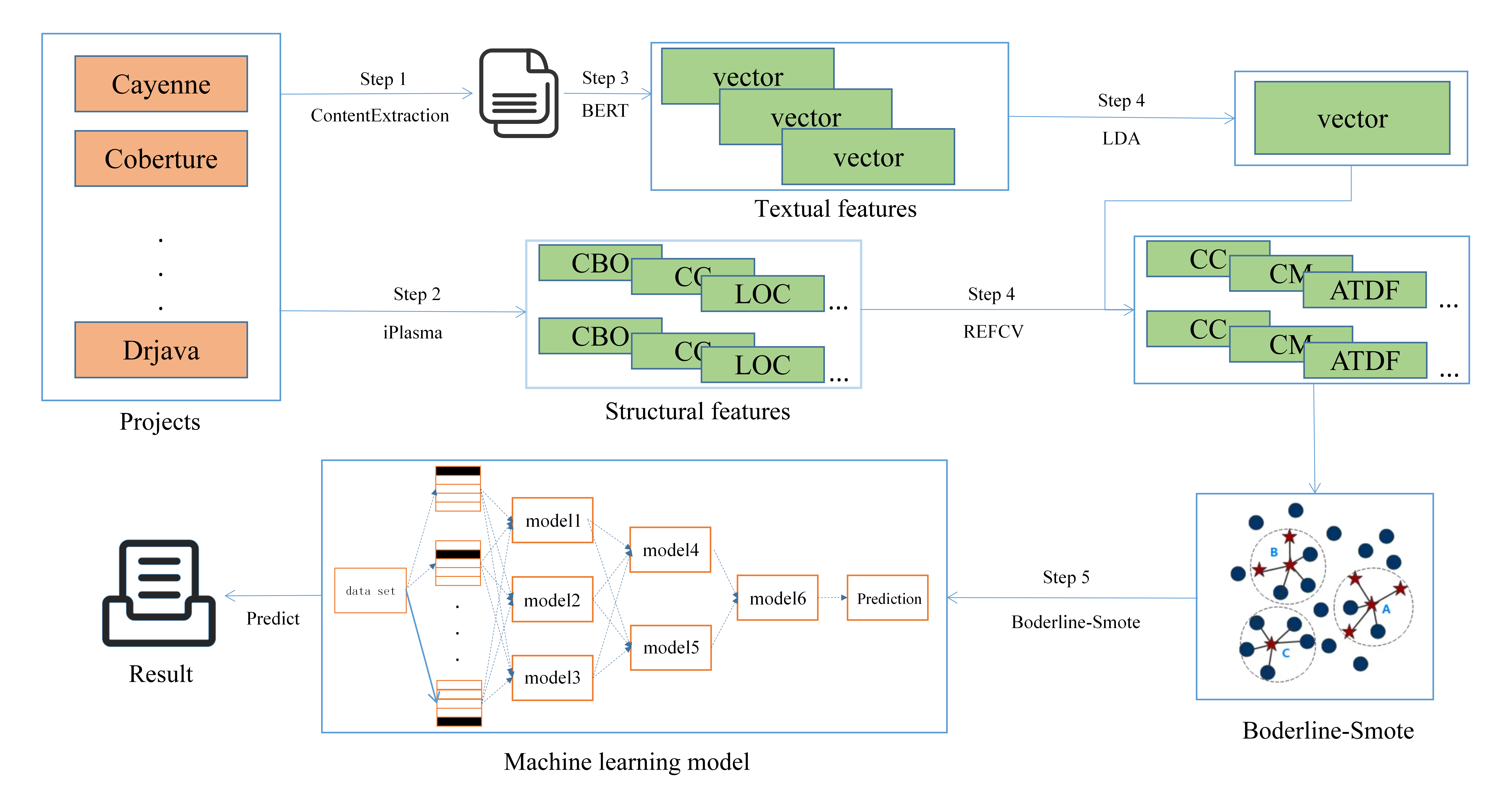
Code smells detection primarily adopts heuristic-based, machine learning, and deep learning approaches, However, to enhance accuracy, most studies employ deep learning methods, but the value of traditional machine learning methods should not be underestimated. Additionally, existing code smells detection methods do not pay sufficient attention to the textual features in the code. To address this issue, this paper proposes a code smell detection method, SCSmell, which utilizes static analysis tools to extract structure features, then transforms the code into txt format using static analysis tools , and inputs it into the BERT pre-training model to extract textual features. The structure features are combined with the textual features to generate sample data and label code smells instances. The REFCV method is then used to filter important structure features. To deal with the issue of data imbalance, the Borderline-SMOTE method is used to generate positive sample data, and a three-layer Stacking model is ultimately employed to detect code smells. In our experiment, we select 44 large actual projects programs as the training and testing sets and conducted smell detection for four types of code smells: brain class, data class, God class, and brain method. The experimental results indicate that the SCSmell method improves the average accuracy by 10.38% compared to existing detection methods, while maintaining high precision, recall, and F1 scores. The SCSmell method is an effective solution for implementing code smells detection.
Downloads
References
F. Palomba, G. Bavota, M. Di Penta, F. Fasano, R. Oliveto, and A. De Lucia, “On the diffuseness and the impact on maintainability of code smells: A large scale empirical investigation,” in Proceedings of the 40th International Conference on Software Engineering, 2018, pp. 482–482.
N. Moha, Y.-G. Guéhéneuc, L. Duchien, and A.-F. Le Meur, “Decor: A method for the specification and detection of code and design smells,” IEEE Transactions on Software Engineering, vol. 36, no. 1, pp. 20–36, 2009.
M. Fokaefs, N. Tsantalis, E. Stroulia, and A. Chatzigeorgiou, “Jdeodorant: Identification and application of extract class refactorings,” in Proceedings of the 33rd International Conference on Software Engineering, 2011, pp. 1037–1039.
R. Marinescu, “Measurement and quality in objectoriented design,” in 21st IEEE International Conference on Software Maintenance (ICSM’05), IEEE, 2005, pp. 701–704.
F. Arcelli Fontana, M. V. Mäntylä, M. Zanoni, and A. Marino, “Comparing and experimenting machine learning techniques for code smell detection,” Empirical Software Engineering, vol. 21, pp. 1143–1191, 2016.
F. Pecorelli, F. Palomba, D. Di Nucci, and A. De Lucia, “Comparing heuristic and machine learning approaches for metric-based code smell detection,” in 2019 IEEE/ACM 27th International Conference on Program Comprehension (ICPC), IEEE, 2019, pp. 93–104.
S. Wang, Y. Zhang, and J. Sun, “Detection of bad smell in code based on bp neural network,” Computer Engineering, vol. 46, no. 10, pp. 216–222, 2020.
H. Liu, Z. Xu, and Y. Zou, “Deep learning based feature envy detection,” in Proceedings of the 33rd ACM/IEEE international conference on automated software engineering, 2018, pp. 385–396.
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
D. H. Wolpert, “Stacked generalization,” Neural networks, vol. 5, no. 2, pp. 241–259, 1992.
H. Han, W.-Y. Wang, and B.-H. Mao, “Borderlinesmote: A new over-sampling method in imbalanced datasets learning,” in International conference on intelligent computing, Springer, 2005, pp. 878–887.
S.-i. Amari and S. Wu, “Improving support vector machine classifiers by modifying kernel functions,” Neural Networks, vol. 12, no. 6, pp. 783–789, 1999.
C. M. Bishop and N. M. Nasrabadi, Pattern recognition and machine learning. Springer, 2006, vol. 4.
T. Łuczak and B. Pittel, “Components of random forests,” Combinatorics, Probability and Computing, vol. 1, no. 1, pp. 35–52, 1992.
Y. Liao and V. R. Vemuri, “Use of k-nearest neighbor classifier for intrusion detection,” Computers & security, vol. 21, no. 5, pp. 439–448, 2002.
Y. Freund and R. E. Schapire, “A decision-theoretic generalization of on-line learning and an application to boosting,” Journal of computer and system sciences, vol. 55, no. 1, pp. 119–139, 1997.
S. R. Safavian and D. Landgrebe, “A survey of decision tree classifier methodology,” IEEE transactions on systems, man, and cybernetics, vol. 21, no. 3, pp. 660–674, 1991.
M. Lanza and R. Marinescu, Object-oriented metrics in practice: using software metrics to characterize, evaluate, and improve the design of object-oriented systems. Springer Science & Business Media, 2007.
K. Cho, B. Van Merriënboer, C. Gulcehre, et al., “Learning phrase representations using rnn encoder-decoder for statistical machine translation,” arXiv preprint arXiv:1406.1078, 2014.
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
H. Guo, R. Tang, Y. Ye, Z. Li, and X. He, “Deepfm: A factorization-machine based neural network for ctr prediction,” arXiv preprint arXiv:1703.04247, 2017.
Z. Y, D. CH, L. H, and G. CY, “Code smell detection approach based on pre-training model and multilevel information,” Journal of Software, vol. 33, no. 5, p. 1551, May 2022.
Y. Zhang, C. Ge, S. Hong, R. Tian, C. Dong, and J. Liu, “Delesmell: Code smell detection based on deep learning and latent semantic analysis,” Knowledge Based Systems, vol. 255, pp. 109–737, 2022.