Mining Common Syntactic Patterns used by Java Programmers
Keywords:
Syntactic patterns, rule mining, Abstract Syntax Trees, association rules, JavaAbstract
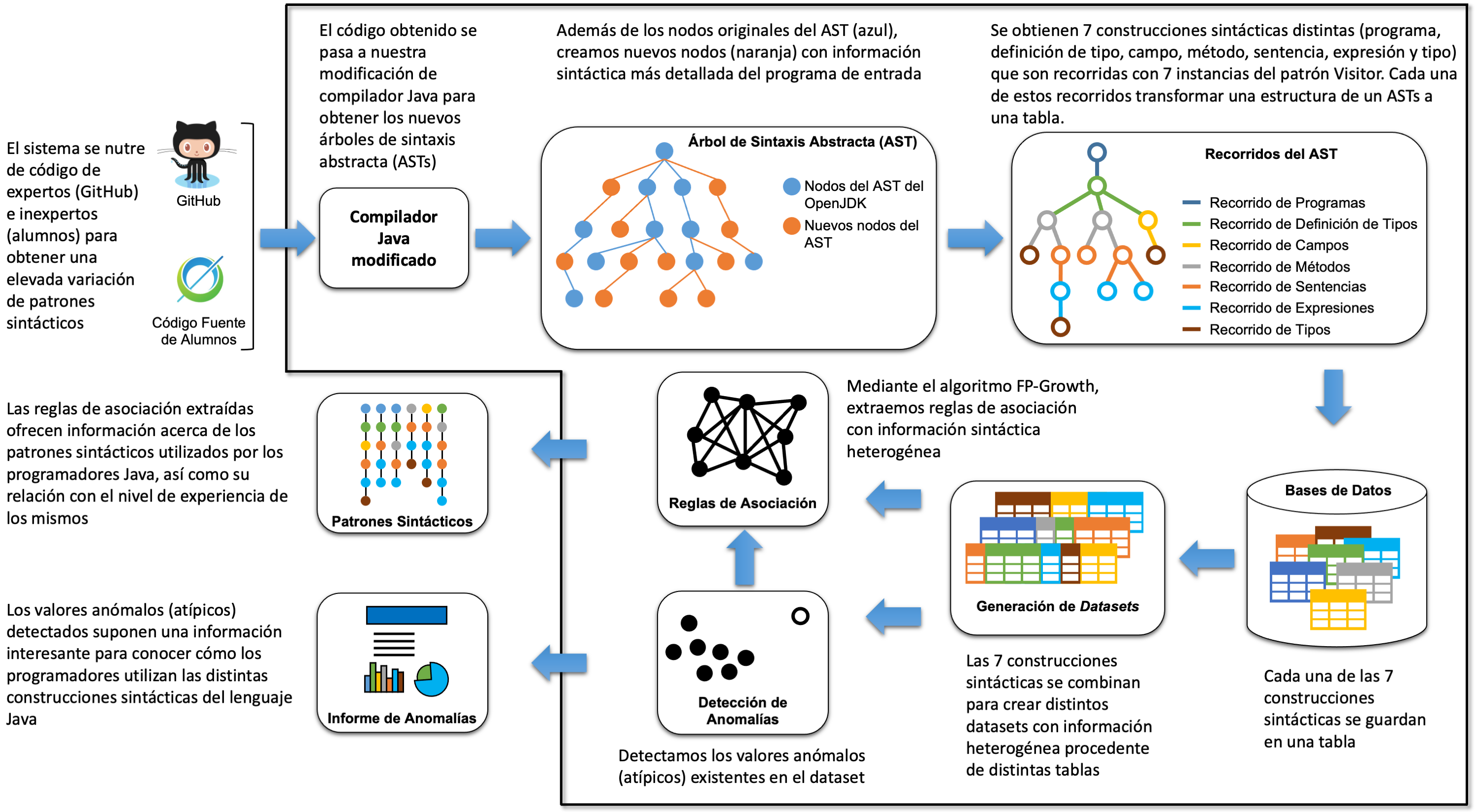
Open source code repositories provide massive data as programs that have been used to develop different tools. These kinds of works have been included in the active Big Code and Mining Software Repositories research fields. Although different machine learning works already classify the syntactic constructs used by programmers, there are no reports about the most common syntactic patterns used by Java programmers. In this article, we describe a system we build to provide such a report. Our system retrieves the syntactic patterns used by Java programmers, distinguishing those utilized by experts and beginners. We also present the anomalies found in the usage of different syntactic constructs. We modify the OpenJDK compiler to double the syntactic information included in its Abstract Syntax Tree (AST), define a mechanism to translate ASTs into n-dimensional vectors, combine the information of different syntax constructs to build heterogeneous patterns, and apply the Frequent Pattern Growth algorithm to mine the syntactic patterns as association rules. The mined patterns allow expressing hierarchical subpatterns connected to one another, providing a high level of expressiveness.
Downloads
References
F. Ortin, J. Escalada, and O. Rodriguez-Prieto, “Big Code: New Opportunities for Improving Software Construction,” J. Softw., vol. 11, pp. 1008–1083, Nov. 2016, DOI: 10.17706/JSW.11.11.1083-1088.
K. Aggarwal, M. Salameh, and A. Hindle. “Using machine translation for converting Python 2 to Python 3 code”. PeerJ PrePrints, Oct. 29, 2015. [Online] DOI: 10.7287/PEERJ.PREPRINTS.1459V1, Accessed on: Jun. 10, 2021.
A. V. M. Barone, and R. Sennrich. “A parallel corpus of Python functions and documentation strings for automated code documentation and code generation,” 2017. [Online]. Available: arXiv:1707.02275v1 [cs.CL].
A. Bhoopchand, T. Rocktäschel, E. Barr, and S. Riedel. “Learning Python Code Suggestion with a Sparse Pointer Network,” 2016. [Online]. Available: arXiv:1611.08307v1 [cs.NE].
S. Bhatia and R. Singh, “Automated correction for syntax errors in programming assignments using Recurrent neural networks,” 2016. [Online]. Available: arXiv:1603.06129v1 [cs.PL].
A. W. Appel, and J. Palsberg, Modern Compiler Implementation in Java, 2nd ed., Cambridge, UK: Cambridge University Press, 2002.
F. Yamaguchi, M. Lottmann, and K. Rieck, “Generalized Vulnerability Extrapolation using Abstract Syntax Trees,” in ACM Int. Conf. Proc. Series, 2012, pp. 359–368, DOI: 10.1145/2420950.2421003.
J. Escalada and F. Ortin, “An Adaptable Infrastructure to Generate Training Datasets for Decompilation Issues,” in Advances in Intelligent Systems and Computing, Cham: Springer International Publishing, 2014, pp. 85–94. DOI: 10.1007/978-3-319-05948-8_9.
F. Ortin, O. Rodriguez-Prieto, N. Pascual, and M. Garcia, “Heterogeneous tree structure classification to label Java programmers according to their expertise level,” Futur. Gener. Comput. Syst., vol. 105, pp. 380–394, 2020, DOI: 10.1016/J.FUTURE.2019.12.016.
V. Iyer, and C. Zilles. “Pattern Census: A Characterization of Pattern Usage in Early Programming Courses,” in Proc. of the 52nd ACM Technical Symp. on Comp. Science Education, 2021, pp. 45–51.
T. Crow, A. Luxton-Reilly, and B. Wuensche. “Intelligent tutoring systems for programming education: a systematic review,” in Proc. of the 20th Australasian Comp. Education Conf., 2018, pp. 53–62.
Oracle, Oracle JDK 9 Documentation - Java Platform, Standard Edition Tools Reference. Accessed on: Jun. 10, 2021. [Online]. Available: https://docs.oracle.com/javase/9/tools/javac.htm#JSWOR627
M. Allamanis, and C. Sutton, “Mining Idioms from Source Code,” in Proc. of the 22nd ACM SIGSOFT Int. Symp. on Foundations of Software Engineering, 2014, pp. 472–483, DOI: 10.1145/2635868.2635901.
I. D. Baxter, A. Yahin, L. Moura, M. Sant’Anna, and L. Bier, “Clone detection using abstract syntax trees,” in Proc. of the Int. Conf. on Software Maintenance, 1998, pp. 368–377, DOI: 10.1109/ICSM.1998.738528.
D. Perez, and S. Chiba, “Cross-language clone detection by learning over abstract syntax trees,” in Int. Conf. on Mining Software Repositories, 2019, pp. 518–528, DOI: 10.1109/MSR.2019.00078.
J. Zeng, K. Ben, X. Li, and X. Zhang, “Fast Code Clone Detection Based on Weighted Recursive Autoencoders,” IEEE Access, vol. 7, pp. 125062–125078, 2019.
L. Büch, and A. Andrzejak, “Learning-Based Recursive Aggregation of Abstract Syntax Trees for Code Clone Detection,” in Proc. of the IEEE Int. Conf. on Software Analysis, Evolution and Reengineering, pp. 95–104, DOI: 10.1109/SANER.2019.8668039.
Z. Lubsen, A. Zaidman, and M. Pinzger, “Using association rules to study the co-evolution of production test code,” in 6th IEEE Int. Working Conf. on Mining Software Repositories, 2009, pp. 151–154, DOI: 10.1109/MSR.2009.5069493.
P. Bian, B. Liang, W. Shi, J. Huang, and Y. Cai, “NAR-Miner: Discovering Negative Association Rules from Code for Bug Detection,” in Proc. of the 2018 26th ACM Joint Meeting on European Software Engineering Conf. and Symp. on the Foundations of Software Engineering, 2018, pp. 411–422, DOI: 10.1145/3236024.3236032.
A. Losada, G. Facundo, M. Garcia, and f. Ortin, “Mining Common Syntactic Patterns used by Java Programmers (support material website),” 2021. [Online]. Available: http://www.reflection.uniovi.es/bigcode/download/2021/ieee-lat.
M. Joglekar, H. Garcia-Molina, and A. Parameswaran, “Interactive Data Exploration with Smart Drill-Down,” IEEE Trans. Knowl. Data Eng., vol. 31, no. 1, pp. 46–60, 2019.
J. W. Tukey, Exploratory Data Analysis. Upper Saddle River, NJ: Pearson, 1977.
R. Agrawal, and R. Srikant, “Fast Algorithms for Mining Association Rules in Large Databases,” in Proc. of the 20th Int. Conf. on Very Large Data Bases, 1994, pp. 487–499.
R. Agrawal, T. Imieliński, and A. Swami, “Mining association rules between sets of items in large databases,” in Proc. of the 1993 ACM SIGMOD Int. Conf. on Manage. of Data - SIGMOD ’93, 1993.
J. Han, M. Kamber, and J. Pei, Data Mining: Concepts and Techniques. Oxford, England: Morgan Kaufmann, 2012.
O. Rodriguez-Prieto, A. Mycroft, and F. Ortin, “An efficient and scalable platform for Java source code analysis using overlaid graph representations,” IEEE Access, vol. 8, pp. 72239–72260, 2020.