Synthesis of Sung Spanish Vowels in Lyrical Singing by Sopranos
Keywords:
Glottal signal, Rosenberg model, singing voice, vibrato effect, voice synthesisAbstract
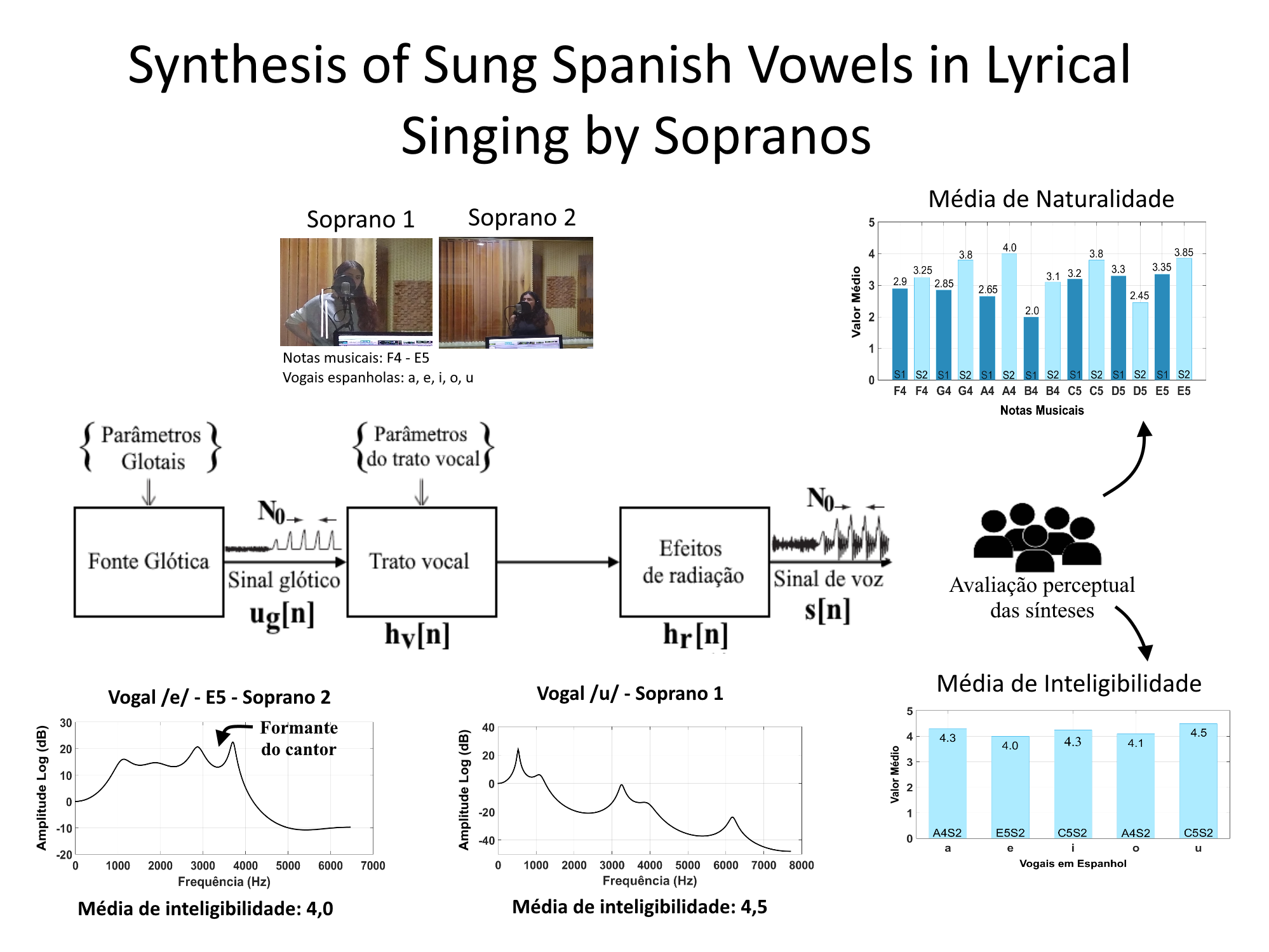
The aim of this paper is perform the synthesis of sung Spanish vowels considering the soprano vocal category of lyrical singers, including variation of sustained pitches with vibrato and tremolo effects, considering sounds from Spanish language. The Fant source-filter theory is used to model the production of the sung vowels: the source is based on the Rosenberg glottal pulse model and the filter (the vocal tract) is composed by an all-pole filter model with formant frequencies and bandwidths from the vowels of the Spanish language, obtained through experimental voice signals from two soprano singers. All the sounds synthesized are available to be accessed and they were submitted to a group of listeners which gave a very good evaluation with respect to the intelligibility and naturalness of the sounds.
Downloads
References
C. C. Lochbaum and J. L. Jr. Kelly, “Speech synthesis,” Proceedings of the Speech Communication Seminar, pp. 583-596, 1962.
M. Mellody, F. Herseth, G. H. Wakefield, “Modal distribution analysis, synthesis, and perception of a soprano’s sung vowels,” Journal of Voice, v. 15, n. 4, pp. 469-482, 2001.
M. Nishimura, K. Hashimoto, K. Oura, Y. Nankaku, k. Tokuda, “Singing Voice Synthesis Based on Deep Neural Networks,” Interspeech, pp. 2478-2482, September 2016.
N. D’Alessandro, P. Woodruff, Y. Fabre, T. Dutoit, S. Le Beux, B. Doval, C. d’Alessandro, “Realtime and accurate musical control of expression in singing synthesis,” Journal on Multimodal User Interfaces, v. 1, n. 1, pp. 31-39, 2007.
T. Nose, M. Kanemoto, T. Koriyama, T. Kobayashi, “Hmm-based expressive singing voice synthesis with singing style control and robust pitch modeling,” Computer Speech & Language, v. 34, n. 1, pp. 308–322, 2015.
L. Ardaillon, Synthesis and expressive transformation of singing voice. Ph.D. thesis, Paris 6, 2017.
J. Sundberg, “Vocal tract resonance in singing,” The NATS Journal, v. 44, n. 4, pp. 11-20, 1988.
P. P. de Juli´an, “Modificaci´on o aggiustamento de las vocales espa˜nolas en el canto l´ırico,” Estudios de fon´etica experimental, pp. 263-293, 2016.
J. Sundberg, “Research on the singing voice in retrospect,” TMH-QPSR, v. 45, n. 1, pp. 11-22, 2003.
M. Garnier, N. Henrich, L. Crevier-Buchman, C. Vincent, J. Smith, J. Wolfe, “Glottal behavior in the high soprano range and the transition to the whistle register,” The Journal of the Acoustical Society of America, v. 131, n. 1, pp. 951-962, 2012.
I. R. Titze, Principles of voice production. Prentice Hall, 1994.
E. Cataldo and C. Soize, “Stochastic mechanical model of vocal folds for producing jitter and for identifying pathologies through real voices,” Journal of biomechanics, v. 74, pp. 126–133, June 2018.
N. H. Bernardoni, Etude de la source glottique en voix parl´ee et chant´ee: mod´elisation et estimation, mesures acoustiques et ´electroglottographiques, perception. Ph.D. thesis, Universit´e Pierre et Marie Curie-Paris VI (UPMC), 2001.
G. Fant, “Acoustic theory of speech production.’sgravenhage: Mouton,” The Netherlands, 1960.
G. Fant, “The source filter concept in voice production,” STL-QPSR, v. 22, n. 1, pp. 21–37, 1981.
M. L. Facal, La voz del cantante: est´udio comparativo del an´alisis objetivo y subjetivo de la voz hablada y cantada. Librer´ıa Akadia Editorial, 2005.
L. R. Rabiner, and R. W. Schafer, Theory and applications of digital speech processing. v. 64, Pearson Upper Saddle River, NJ, 2011.
A. E. Rosenberg, “Effect of glottal pulse shape on the quality of natural vowels,” The Journal of the Acoustical Society of America, v. 49, n. 2B, pp. 583-590, 1971.
B. Doval, C. d’Alessandro, N. Henrich, “The spectrum of glottal flow models,” Acta acustica united with acustica, v. 92, n. 6, pp. 1026–1046, 2006.
M. Hirano, S. Hibi, S. Hagino, “Physiological aspects of vibrato,” Vibrato, pp. 9-33, 1995.
M. Salas, “Aplicaciones del an´alisis ac´ustico en los estudios de la voz humana,” Seminario Internacional de Ac´ustica, 2003.
L. Regnier, G. Peeters, “Singing voice detection in music tracks using direct voice vibrato detection,” IEEE International Conference on Acoustics, Speech and Signal Processing, pp. 1685–1688, 2009.
S. Hertegard, J. Gauffin, J. Sundberg, “Open and covered fiberoptics, inverse singing as studied by means of filtering, and spectral analysis,” J Voice, v. 4, pp. 220-230, 1990.
M. Kob, N. Henrich, H. Herzel, D. Howard, I. Tokuda, J. Wolfe, “Analysing and understanding the singing voice: recent progress and open questions,” Current bioinformatics, v. 6, n. 3, pp. 362–374, 2011.
T. J. Millhouse, F. Clermont, “Perceptual characterisation of the singerˆaC™s formant region: a preliminary study,” Proceedings of the Eleventh Australian International Conference on Speech Science and Technology, pp. 253–258, 2006.
D. R. Allen, W. J. Strong, “A model for the synthesis of natural sounding vowels,” The Journal of the Acoustical Society of America, v. 78, n. 1, pp. 58-69, 1985.
E. Cataldo, F. R. Leta, J. Lucero, L. Nicolato, “Synthesis of voiced sounds using low-dimensional models of the vocal cords and timevarying subglottal pressure,” Mechanics Research Communications, v. 33, n. 2, pp. 250–260, 2006.
G. Berndtsson, J. Sundberg, “Perceptual significance of the center frequency of singer’s formant,” Scandinavian Journal of Logopedics and Phoniatrics, v. 20, n. 1, pp. 35–41, 1995.
R. Weiss, W. Brown Jr, J. Moris, “Singer’s formant in sopranos: fact or fiction?,” Journal of Voice, v. 15, n. 4, pp. 457–468, 2001.