A New Strategy to Seed Selection for the High Recall Task
Keywords:
Information Retrieval, High-Recall Information Retrieval, Cold start, Active learningAbstract
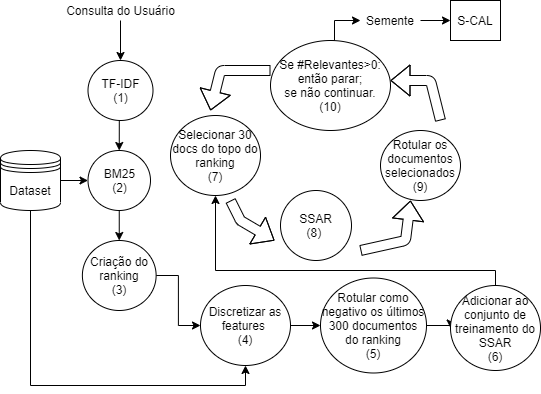
High Recall Information Retrieval (HIRE) aims at identifying all (or nearly all) relevant documents given a query. HIRE, for example, is used in the systematic literature review task, where the goal is to identify all relevant scientific articles. The documents selected by HIRE as relevant define the user effort to identify the target information. On this way, one of HIRE goals is only to return relevant documents avoiding overburning the user with non-relevant information. Traditionally, supervised machine learning algorithms are used as HIRE' core to produce a ranking of relevant documents (e.g. SVM). However, such algorithms depend on an initial training set (seed) to start the process of learning. In this work, we propose a new approach to produce the initial seed for HIRE focus on reducing the user effort. Our approach combines an active learning approach with a raking strategy to select only the informative examples. The experimentation shows that our approach is able to reduce until 18\% the labeling effort with competitive recall.
Downloads
References
C. D. Manning, P. Raghavan, and H. Sch ̈utze, Introduction to information retrieval. Cambridge University Press, 2018.
A. Roegiest, “On design and evaluation of high-recall retrieval systems for electronic discovery,” 2017
G. V. Cormack and M. R. Grossman, “Autonomy and reliability of con-tinuous active learning for technology-assisted review,”arXiv preprintarXiv:1504.06868, 2015.
Z. Yu, N. A. Kraft, and T. Menzies, “Finding better active learnersfor faster literature reviews,”Empirical Software Engineering, 2018.[Online]. Available: https://doi.org/10.1007/s10664-017-9587-0
B. Settles, “Active learning literature survey,” University of Wisconsin–Madison, Computer Sciences Technical Report 1648, 2009.
G. V. Cormack and M. R. Grossman, “Scalability of continuous active learning for reliable high-recall text classification,” pp. 1039–1048, 2016.
M. Fisichella, R. Kawase, and U. Gadiraju, “Automatic classification of documents in cold-start scenarios,” 2009.
E. Kanoulas, D. Li, L. Azzopardi, and R. Spijker, “Clef 2017 technologically assisted reviews in empirical medicine overview,” inCEURWorkshop Proceedings, vol. 1866, 2017, pp. 1–29.
R. Silva, M. A. Goncalves, and A. Veloso, “Rule-based active sampling for learning to rank,”Machine Learning and Knowledge Discovery in Databases Lecture Notes in Computer Science, p. 240–255, 2011.
S. Qaiser and R. Ali, “Text mining: Use of tf-idf to examine therelevance of words to documents,”International Journal of ComputerApplications, vol. 181, no. 1, p. 25–29, 2018.
Y. Goodfellow and A. Courville,Machine Learning Basics. The MITPress, 2016, p. 95–160.
Z. Yu and T. Menzies, “Fast2: An intelligent assistant for finding relevantpapers,”Expert Systems with Applications, vol. 120, pp. 57 – 71, 2019.
G. V. Cormack and M. R. Grossman, “Engineering quality and reliability in technology-assisted review,” inACM SIGIR, 2016, pp. 75–84.
Y. Meng, J. Shen, C. Zhang, and J. Han, “Weakly-supervised neural text classification,” in Proceedings of the 27th ACM International Conference on Information and Knowledge Management, 2018, pp. 983–992.
E. Kanoulas, D. Li, L. Azzopardi, and R. Spijker, “Clef 2017 technologically assisted reviews in empirical medicine overview,” inCEURWorkshop Proceedings, vol. 1866, 2017, pp. 1–29