Effects on Time and Quality of Short Text Clustering during Real-Time Presentations
Keywords:
Text Mining, TF-IDF, K-Means, Short Phrases, Short Text, Sentences, Clustering, InteractivityAbstract
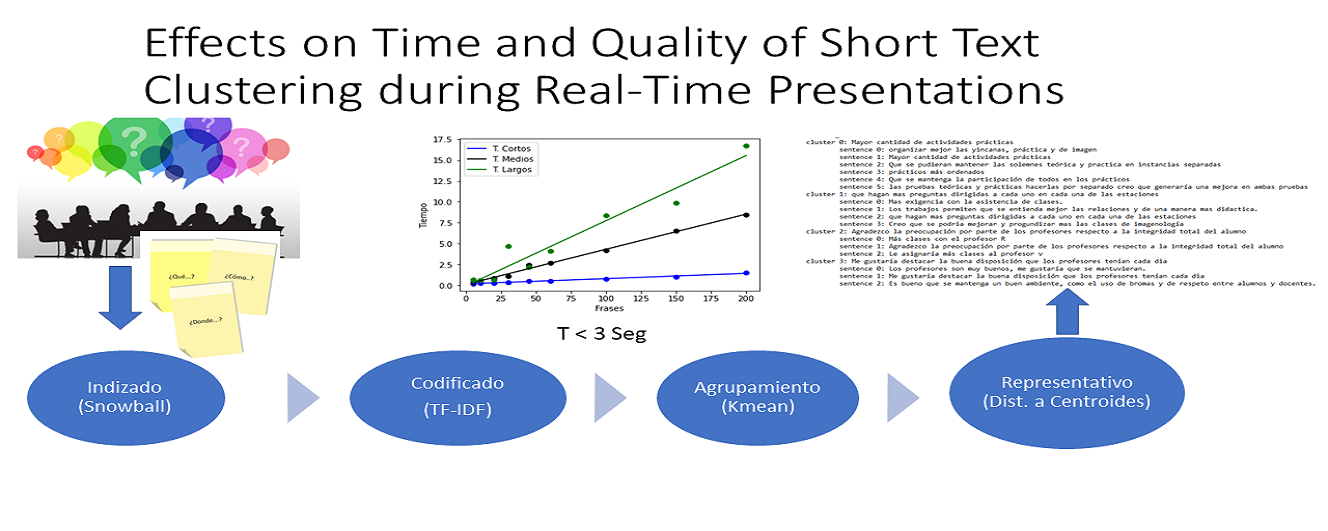
Technologies for live presentations should consider users' capabilities to manage large amounts of data in real-time, particularly, exchanges of short texts (e.g., phrases). This study examines the effects on time and quality of text clustering algorithms applied to short, medium, and long size texts, and examines whether short text clustering shows a reasonable performance for live presentations. We run several simulations in which we varied the number of phrases (from 5 to 200) contained in each text type (long, medium, and short) and the number of generated clusters (from 2 to 10). The algorithms used were snowball steamers, TF-IDF, and K-means for clustering; and the text types were Reuters, 20 NewsGroup and an experimental data set, for the long, medium, and short size texts, respectively. The first result showed that text size had a large effect on the algorithm’s execution time, with the shortest average time for the short texts and longer average time for the longest texts. The second result showed that the number of phrases in each text type significantly predicts execution time but not the number of clusters generated by K-means. Inertia and purity measures were used to test the quality of the clusters generated. Text size, number of phrases and number of clusters predict inertia; showing the lowest inertia for the short texts. Purity measures were like previously reported results for all text types. Thus, clustering algorithms for short texts can confidently be used in real-time presentations.
Downloads
References
A. N. Srivastava and M. Sahami, Text Mining, 1st ed. New York: Chapman and Hall/CRC, 2009.
W. F. Cody, J. T. Kreulen, V. Krishna, and W. S. Spangler, “The integration of business intelligence and knowledge management,” IBM Syst. J., vol. 41, no. 4, pp. 697–713, 2002, doi: 10.1147/sj.414.0697.
A. I. De Lima, A. B. Argenta, I. C. Zattar, and M. Kleina, “Applying Text Mining to Identify Photovoltaic Technologies,” IEEE Lat. Am. Trans., vol. 17, no. 5, pp. 727–733, 2019, doi: 10.1109/TLA.2019.8891940.
R. Neto, R. Ribeiro, and A. Emília, “Investigating the influence of groups of variables on the task of predicting the age of an author in blog posts,” IEEE Lat. Am. Trans., vol. 18, no. 5, pp. 838–844, 2020, doi: 10.1109/TLA.2020.9082911.
S. Schreibman, R. R. Siemens, and J. Unsworth, A New Companion to Digital Humanities. Chichester, UK: John Wiley & Sons, Ltd, 2015.
L. Kotlerman, I. Dagan, and O. Kurland, “Clustering small-sized collections of short texts,” Inf. Retr. J., vol. 21, no. 4, pp. 273–306, 2018, doi: 10.1007/s10791-017-9324-8.
C. Greenhow, J. Li, and M. Mai, “From tweeting to meeting: Expansive professional learning and the academic conference backchannel,” Br. J. Educ. Technol., vol. 50, no. 4, pp. 1656–1672, Jul. 2019, doi: 10.1111/bjet.12817.
W. M. Kappers and S. Cutler, “Poll everywhere! even in the classroom: An investigation into the impact of using polleverywhere in a large-lecture classroom,” in ASEE Annual Conference and Exposition, Conference Proceedings, 2014, vol. 6, no. 20, pp. 140–145.
M. Compton and J. Allen, “Student Response Systems: a rationale for their use and a comparison of some cloud based tools,” Compass J. Learn. Teach., vol. 11, no. 1, pp. 267–271, Apr. 2018, doi: 10.21100/compass.v11i1.696.
S. Vincent, “Sentence length: why 25 words is our limit,” Inside GOV.UK, 2014. https://insidegovuk.blog.gov.uk/2014/08/04/sentence-length-why-25-words-is-our-limit/ (accessed Jul. 14, 2020).
L. M. Goldstein and S. M. Conrad, “Student Input and Negotiation of Meaning in ESL Writing Conferences,” TESOL Q., vol. 24, no. 3, p. 443, 1990, doi: 10.2307/3587229.
J. R. Cox, “Enhancing student interactions with the instructor and content using pen-based technology, youtube videos, and virtual conferencing,” Biochem. Mol. Biol. Educ., vol. 39, no. 1, pp. 4–9, Jan. 2011, doi: 10.1002/bmb.20443.
L. M. Shah, E. P. Quigley, and R. H. Wiggins, “The Next Wave: Confexting,” J. Digit. Imaging, vol. 25, no. 1, pp. 25–29, 2012, doi: 10.1007/s10278-011-9398-6.
X. Chen, M. Vorvoreanu, and K. P. C. Madhavan, “Mining Social Media Data for Understanding Students’ Learning Experiences,” IEEE Trans. Learn. Technol., vol. 7, no. 3, pp. 246–259, Jul. 2014, doi: 10.1109/TLT.2013.2296520.
A. Shimada, F. Okubo, C. Yin, and H. Ogata, “Automatic Summarization of Lecture Slides for Enhanced Student Preview -Technical Report and User Study-,” IEEE Trans. Learn. Technol., vol. 11, no. 2, pp. 165–178, Apr. 2018, doi: 10.1109/TLT.2017.2682086.
P. Vrablecova and M. Simko, “Supporting Semantic Annotation of Educational Content by Automatic Extraction of Hierarchical Domain Relationships,” IEEE Trans. Learn. Technol., vol. 9, no. 3, pp. 285–298, Jul. 2016, doi: 10.1109/TLT.2016.2546255.
A. Szmelter-Jarosz and J. Rześny-Cieplińska, “Priorities of Urban Transport System Stakeholders According to Crowd Logistics Solutions in City Areas. A Sustainability Perspective,” Sustainability, vol. 12, no. 1, p. 317, Dec. 2019, doi: 10.3390/su12010317.
G. Somprasertsri and P. Lalitrojwong, “Mining feature-opinion in online customer reviews for opinion summarization,” J. Univers. Comput. Sci., vol. 16, no. 6, pp. 938–955, 2010, doi: 10.3217/jucs-016-06-0938.
T. Jo, Text Mining, 2nd ed., vol. 45. Cham: Springer International Publishing, 2019.
P. Shrestha, C. Jacquin, and B. Daille, “Clustering Short Text and Its Evaluation,” in Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), vol. 7182 LNCS, no. PART 2, 2012, pp. 169–180.
L. Cagnina, M. Errecalde, D. Ingaramo, and P. Rosso, “An efficient Particle Swarm Optimization approach to cluster short texts,” Inf. Sci. (Ny)., vol. 265, pp. 36–49, May 2014, doi: 10.1016/j.ins.2013.12.010.
J. M. Sanchez-Gomez, M. A. Vega-Rodríguez, and C. J. Pérez, “An Indicator-based Multi-Objective Optimization Approach Applied to Extractive Multi-Document Text Summarization,” IEEE Lat. Am. Trans., vol. 17, no. 8, pp. 1291–1299, 2019, doi: 10.1109/TLA.2019.8932338.
J. Rashid, S. M. A. Shah, and A. Irtaza, “Fuzzy topic modeling approach for text mining over short text,” Inf. Process. Manag., vol. 56, no. 6, p. 102060, Nov. 2019, doi: 10.1016/j.ipm.2019.102060.
M. R. H. Rakib, N. Zeh, M. Jankowska, and E. Milios, “Enhancement of short text clustering by iterative classification,” in Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), vol. 12089 LNCS, Cham: Springer, 2020, pp. 105–117.
D. Wu, M. Zhang, C. Shen, Z. Huang, and M. Gu, “BTM and GloVe Similarity Linear Fusion-Based Short Text Clustering Algorithm for Microblog Hot Topic Discovery,” IEEE Access, vol. 8, pp. 32215–32225, 2020, doi: 10.1109/ACCESS.2020.2973430.
C. Hennig, “Cluster Validation by Measurement of Clustering Characteristics Relevant to the User,” in Data Analysis and Applications 1, Hoboken, NJ, USA: John Wiley & Sons, Inc., 2019, pp. 1–24.
B. Altınel and M. C. Ganiz, “Semantic text classification: A survey of past and recent advances,” Inf. Process. Manag., vol. 54, no. 6, pp. 1129–1153, Nov. 2018, doi: 10.1016/j.ipm.2018.08.001.
Z. Qiu and H. Shen, “User clustering in a dynamic social network topic model for short text streams,” Inf. Sci. (Ny)., vol. 414, pp. 102–116, Nov. 2017, doi: 10.1016/j.ins.2017.05.018.
L. Yang, X. Cai, Y. Zhang, and P. Shi, “Enhancing sentence-level clustering with ranking-based clustering framework for theme-based summarization,” Inf. Sci. (Ny)., vol. 260, pp. 37–50, Mar. 2014, doi: 10.1016/j.ins.2013.11.026.
B. Liu, Sentiment analysis: Mining opinions, sentiments, and emotions. Cambridge: Cambridge University Press, 2015.
D. Sahoo and R. Balabantaray, “A novel approach to sentence clustering,” in 2016 International Conference on Computing, Communication and Automation (ICCCA), Apr. 2016, pp. 1–6, doi: 10.1109/CCAA.2016.7813697.
A. Khan et al., “Abstractive Text Summarization based on Improved Semantic Graph Approach,” Int. J. Parallel Program., vol. 46, no. 5, pp. 992–1016, 2018, doi: 10.1007/s10766-018-0560-3.
H.-T. Zheng, B.-Y. Kang, and H.-G. Kim, “Exploiting noun phrases and semantic relationships for text document clustering,” Inf. Sci. (Ny)., vol. 179, no. 13, pp. 2249–2262, Jun. 2009, doi: 10.1016/j.ins.2009.02.019.
W. B. A. Karaa and N. Dey, Mining Multimedia Documents. New York: Chapman and Hall/CRC, 2017.
C. Zhang and J. Han, Multidimensional Mining of Massive Text Data, vol. 11, no. 2. Morgan & Claypool Publishers, 2019.
J. Peña, J. Lozano, and P. Larrañaga, “An empirical comparison of four initialization methods for the K-Means algorithm,” Pattern Recognit. Lett., vol. 20, no. 10, pp. 1027–1040, Oct. 1999, doi: 10.1016/S0167-8655(99)00069-0.
P. Bholowalia and A. Kumar, “EBK-Means: A Clustering Technique based on Elbow Method and K-Means in WSN,” Int. J. Comput. Appl., vol. 105, no. 9, pp. 17–24, 2014, [Online]. Available: https://www.ijcaonline.org/archives/volume105/number9/18405-9674.
M. E. Ares, J. Parapar, and Á. Barreiro, “An experimental study of constrained clustering effectiveness in presence of erroneous constraints,” Inf. Process. Manag., vol. 48, no. 3, pp. 537–551, 2012, doi: 10.1016/j.ipm.2011.08.006.
J. Nielsen, Usability engineering. Elsevier, 2004.
M. Periano, El Enemigo Conoce el Sistema. Debate, 2019.
S. Sinclair and G. Rockwell, “Text Analysis and Visualization,” in A New Companion to Digital Humanities, Chichester, UK: John Wiley & Sons, Ltd, 2015, pp. 274–290.
R. Parasuraman, T. B. Sheridan, and C. D. Wickens, “A Model for Types and Levels of Human Interaction with Automation,” IEEE Trans. Syst. Man, Cybern. - Part A Syst. Humans, vol. 30, no. 3, pp. 286–297, May 2000, doi: 10.1109/3468.844354.
M. F. Porter, “An algorithm for suffix stripping,” Program, vol. 40, no. 3, pp. 211–218, Jul. 2006, doi: 10.1108/00330330610681286.
C. D. Manning, P. Raghavan, and H. Schutze, Introduction to Information Retrieval, 1st ed. Cambridge: Cambridge University Press, 2008.
J. A. Hartigan and M. A. Wong, “Algorithm AS 136: A K-Means Clustering Algorithm,” Appl. Stat., vol. 28, no. 1, p. 100, 1979, doi: 10.2307/2346830.
T. Korenius, J. Laurikkala, and M. Juhola, “On principal component analysis, cosine and Euclidean measures in information retrieval,” Inf. Sci. (Ny)., vol. 177, no. 22, pp. 4893–4905, 2007, doi: 10.1016/j.ins.2007.05.027.
S. Hettich and S. D. Bay, “The UCI KDD Archive,” 1999. http://kdd.ics.uci.edu/ (accessed Jul. 14, 2020).
P. Fabian et al., “Scikit-learn: Machine Learning in Python,” J. Mach. Learn. Res., vol. 12, no. 85, pp. 2825–2830, 2011, [Online]. Available: http://scikit-learn.sourceforge.net.
D. Fuentealba, K. Liu, and W. Li, “Organisational Responsiveness Through Signs,” in IFIP Advances in Information and Communication Technology, vol. 477, 2016, pp. 117–126.
M. L. McHugh, “Interrater Reliability: the Kappa Statistic,” Biochem. Medica, vol. 22, no. 3, pp. 276–282, 2012, doi: 10.11613/BM.2012.031.
K. Liu and W. Li, Organisational Semiotics for Business Informatics. London and New York: Routledge, 2014.