Automated Generation of Optimized Code Implementing SVM models on GPUs
Keywords:
GPU, code implementation, SVMAbstract
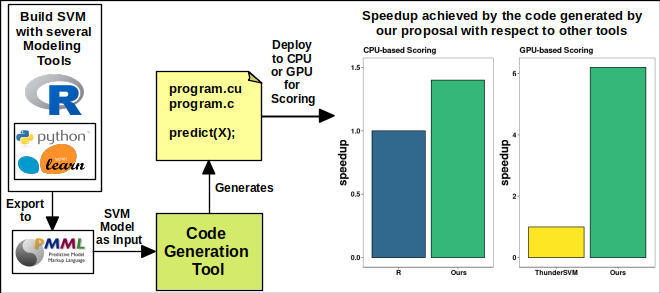
Deploying Support Vector Machine (SVM) models is challenging, since these contain complex math and logic, and also can be composed of a large number of real-valued coefficients; therefore, when performed by humans, the deployment is a slow and error-prone process. From the premise that the process of translating a machine learned predictive model into source code is deterministic and, hence, automatable, this paper's main contribution is demonstrating that it is possible to automate the generation of source code able to efficiently implement SVM models on Graphic Processing Units (GPU), and thus facilitate their operationalization. This research presents: guidelines for the automatic source code generation and efficient execution of SVM models, including code generation for specialized architectures such as GPUs using the Computed Unified Device Architecture (CUDA) platform/language; experimental evidence showing that the resulting source code implements these models efficiently; and a detailed description of the generated source code from sequential up to an optimized version of parallel code. Experiments with a large data set sized up to 9 GB were conducted to show the proposal's feasibility and scalability; such experiments showed an average speed-up of 112.71 times over the sequential, CPU-based, execution of SVMs; additionally, demonstrated a speed-up of 6.2 with respect to other SVM modeling tools running on GPU.
Downloads