Reconstructing fundamental frequency from noisy speech using initialized autoencoders
Keywords:
Deep Learning, fundamental frequency, Neural Network, lstmAbstract
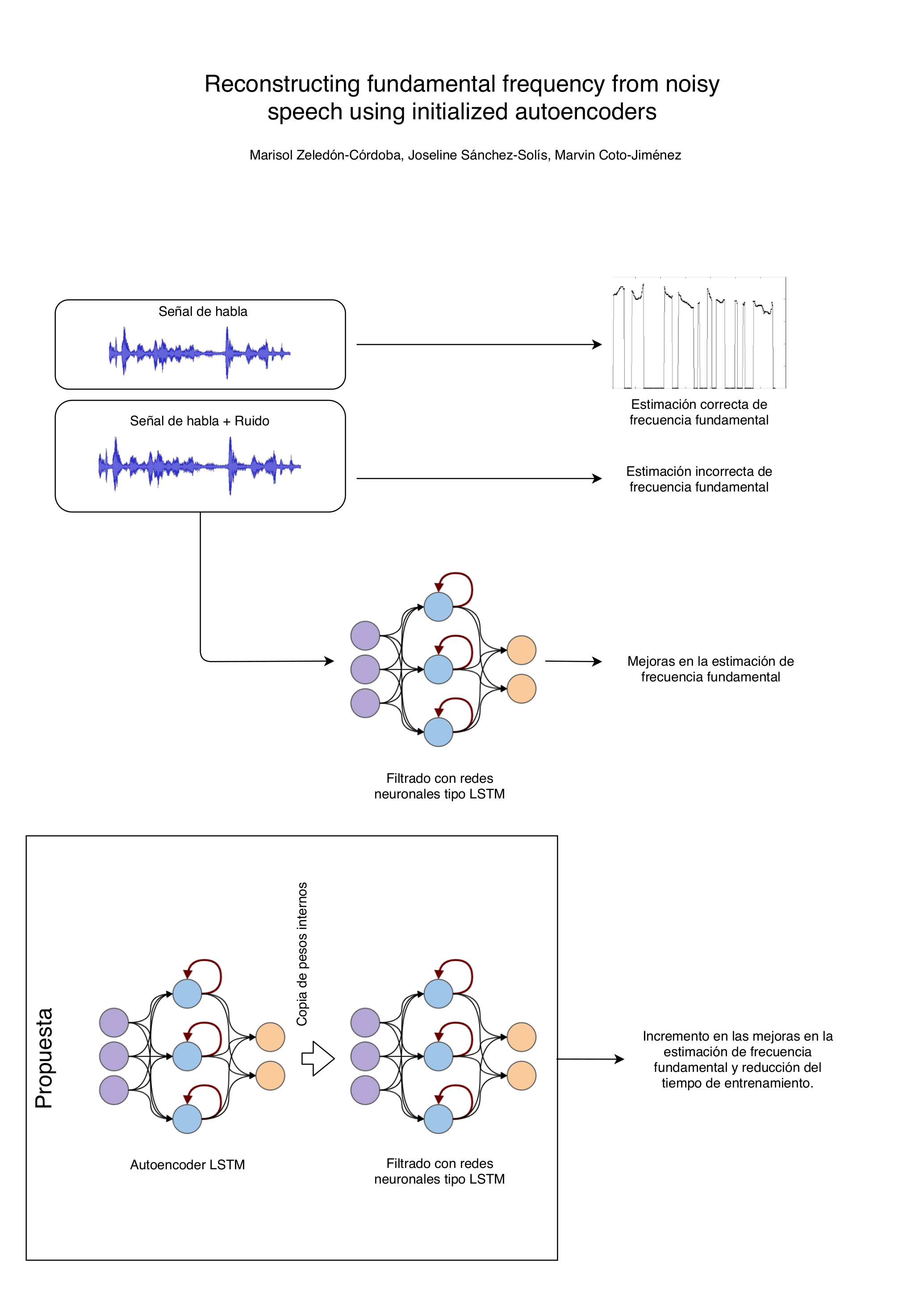
In this paper, we present a new approach for fundamental frequency (f0) detection in noisy speech, based on Long Short-term Memory Neural Networks (LSTM). f0 is one of the most important parameters of human speech. Its detection is relevant in many speech signal processing areas and remains an important challenge for severely degraded signals. In previous references for f0 detection in speech enhancement and noise reduction tasks, LSTM has been initialized with random weights, following a back-propagation through time algorithm to adjust them. Our proposal is an alternative for a more efficient initialization, based on the weights of an Autoassociative network. This initialization is a better starting point for the f0 detection in noisy speech. We show the advantages of pre-training using objective measures for the parameter and the training process, with artificial and natural noise added at different signal-to-noise levels. Results show the performance of the LSTM increases in comparison to the random initialization, and represents a significant improvement in comparison with traditional initialization of neural networks for f0 detection in noisy conditions.
Downloads
References
F. Weninger, J. Geiger, M. W¨ollmer, B. Schuller, and G. Rigoll, “Feature enhancement by deep lstm networks for asr in reverberant multisource environments,” Computer Speech & Language, vol. 28, no. 4, pp. 888–902, 2014.
D. Bagchi, M. I. Mandel, Z. Wang, Y. He, A. Plummer, and E. Fosler-Lussier, “Combining spectral feature mapping and multi-channel modelbased source separation for noise-robust automatic speech recognition,” in 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU). IEEE, 2015, pp. 496–503.
K. Wu, D. Zhang, and G. Lu, “ipeeh: Improving pitch estimation by enhancing harmonics,” Expert Systems with Applications, vol. 64, pp. 317–329, 2016.
J. Du, Q. Wang, T. Gao, Y. Xu, L.-R. Dai, and C.-H. Lee, “Robust speech recognition with speech enhanced deep neural networks,” in 15th Annual Conference of the International Speech Communication Association, 2014.
K. Han, Y. He, D. Bagchi, E. Fosler-Lussier, and D. Wang, “Deep neural network based spectral feature mapping for robust speech recognition,” in Sixteenth Annual Conference of the International Speech Communication Association, 2015.
K. Han and D. Wang, “Neural network based pitch tracking in very noisy speech,” IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), vol. 22, no. 12, pp. 2158–2168, 2014.
M. L. Seltzer, D. Yu, and Y. Wang, “An investigation of deep neural networks for noise robust speech recognition,” in 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 2013, pp. 7398–7402.
O. Abdel-Hamid, A.-r. Mohamed, H. Jiang, and G. Penn, “Applying convolutional neural networks concepts to hybrid nn-hmm model for speech recognition,” in 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2012, pp. 4277– 4280.
J. Huang and B. Kingsbury, “Audio-visual deep learning for noise robust speech recognition,” in 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 2013, pp. 7596–7599.
M. Coto-Jim´enez and J. Goddard-Close, “Lstm deep neural networks postfiltering for enhancing synthetic voices,” International Journal of Pattern Recognition and Artificial Intelligence, vol. 32, no. 01, p. 1860008, 2018.
G. Hinton, L. Deng, D. Yu, G. Dahl, A.-r. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, B. Kingsbury et al., “Deep neural networks for acoustic modeling in speech recognition,” IEEE Signal Processing Magazine, vol. 29, 2012.
M. Coto-Jim´enez, J. Goddard-Close, and F. Mart´ınez-Licona, “Improving automatic speech recognition containing additive noise using deep denoising autoencoders of lstm networks,” in International Conference on Speech and Computer. Springer, 2016, pp. 354–361.
T. Nakashika, R. Takashima, T. Takiguchi, and Y. Ariki, “Voice conversion in high-order eigen space using deep belief nets.” in Interspeech, 2013, pp. 369–372.
B. Liu, J. Tao, D. Zhang, and Y. Zheng, “A novel pitch extraction based on jointly trained deep blstm recurrent neural networks with bottleneck features,” in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2017, pp. 336–340.
I. Thoidis, L. Vrysis, K. Pastiadis, K. Markou, and G. Papanikolaou, “Investigation of an encoder-decoder lstm model on the enhancement of speech intelligibility in noise for hearing impaired listeners,” in Audio Engineering Society Convention 146. Audio Engineering Society, 2019.
G. E. Dahl, D. Yu, L. Deng, and A. Acero, “Context-dependent pretrained deep neural networks for large-vocabulary speech recognition,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 20, no. 1, pp. 30–42, 2011.
A. Van Den Oord, S. Dieleman, and B. Schrauwen, “Transfer learning by supervised pre-training for audio-based music classification,” in Conference of the International Society for Music Information Retrieval (ISMIR 2014), 2014.
J. Donahue, Y. Jia, O. Vinyals, J. Hoffman, N. Zhang, E. Tzeng, and T. Darrell, “Decaf: A deep convolutional activation feature for generic visual recognition,” in International Conference on Machine Learning, 2014, pp. 647–655.
K. Vesel`y, M. Hannemann, and L. Burget, “Semi-supervised training of deep neural networks,” in 2013 IEEE Workshop on Automatic Speech Recognition and Understanding. IEEE, 2013, pp. 267–272.
Y. Fan, Y. Qian, F.-L. Xie, and F. K. Soong, “Tts synthesis with bidirectional lstm based recurrent neural networks,” in 15th Annual Conference of the International Speech Communication Association, 2014.
S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997.
A. Graves, N. Jaitly, and A.-r. Mohamed, “Hybrid speech recognition with deep bidirectional lstm,” in 2013 IEEE Workshop on Automatic Speech Recognition and Understanding. IEEE, 2013, pp. 273–278.
M. Coto-Jim´enez, “Improving post-filtering of artificial speech using pre-trained lstm neural networks,” Biomimetics, vol. 4, no. 2, p. 39, 2019.
F. A. Gers, N. N. Schraudolph, and J. Schmidhuber, “Learning precise timing with lstm recurrent networks,” Journal of Machine Learning Research, vol. 3, no. Aug, pp. 115–143, 2002.
P. Vincent, H. Larochelle, I. Lajoie, Y. Bengio, and P.-A. Manzagol, “Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion,” Journal of Machine Learning Research, vol. 11, no. Dec, pp. 3371–3408, 2010.
L.-H. Chen, T. Raitio, C. Valentini-Botinhao, Z.-H. Ling, and J. Yamagishi, “A deep generative architecture for postfiltering in statistical parametric speech synthesis,” IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), vol. 23, no. 11, pp. 2003–2014, 2015.
J. Kominek and A. W. Black, “The cmu arctic speech databases,” in Fifth ISCA Workshop on Speech Synthesis, 2004.
D. Erro, I. Sainz, I. Saratxaga, E. Navas, and I. Hern´aez, “Mfcc+ f0 extraction and waveform reconstruction using hnm: preliminary results in an hmm-based synthesizer,” Proc. FALA, pp. 29–32, 2010.
J. P. Arias, N. B. Yoma, and H. Vivanco, “Automatic intonation assessment for computer aided language learning,” Speech communication, vol. 52, no. 3, pp. 254–267, 2010.