Throughput Unfairness in Fair Arbitration Interconnection-Buses for Aerospace Embedded Systems
Keywords:
Fairness, arbitration, bus, aerospace, embedded systemsAbstract
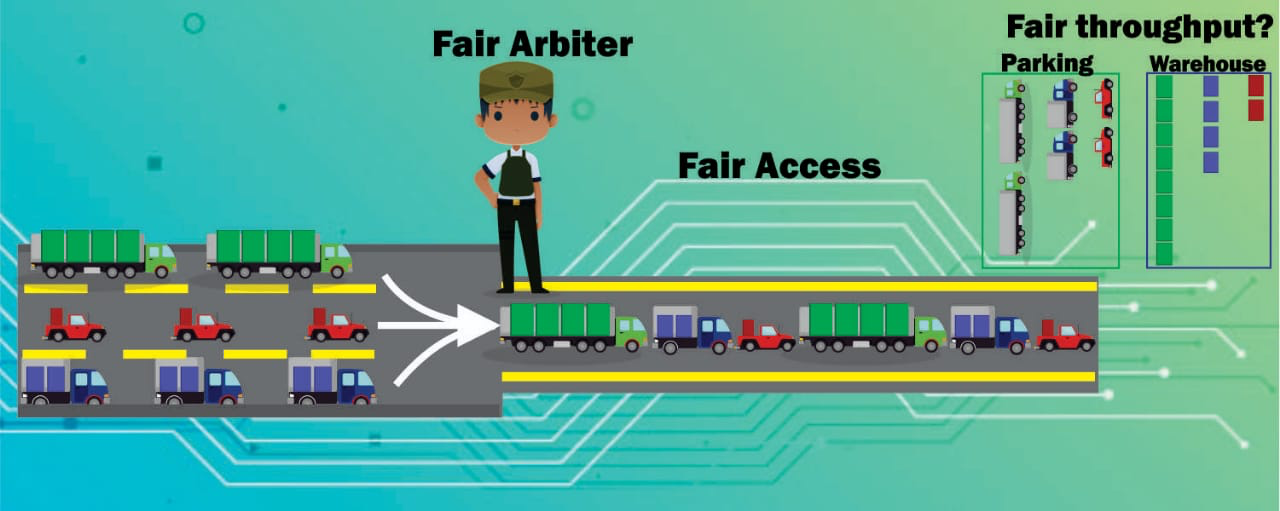
Currently, embedded systems are composed of processors, memories, and Intellectual Property Cores (IP Cores) interconnected to develop a set of specific tasks. Therefore, the selection of an appropriate interconnection architecture is critical in terms of system performance and functionality. A Network-on-Chip provides an efficient and scalable interconnection solution when there are a large number of elements in the system. However, the bus-based interconnection system remains the best option to connect a few cores. The bus arbiter uses an allocation policy to select which IP Core obtains access to the bus. The so-called fair policies ensure that all processors in the system have the same opportunity to access the bus. However, they fail to offer a fair share of the bandwidth or transmission rate, especially when there are heterogeneous IP Cores. As a study case, we analyze an embedded aerospace system for earth observation. Different IP Cores preprocess satellite images at distinct execution times -and unbalanced processing ratesaffecting the delivery rate of images to earth. We study the phenomenon of uneven bus transmission rates due to improper bus allocation using policies such as Round Robin, FIFO, and Lottery. Also, we propose a metric to compute the maximum number of IP Cores without bus saturation.
Downloads
References
F. Poletti, D. Bertozzi, L. Benini, and A. Bogliolo, “Performance Analysis of Arbitration Policies for SoC Communication Architectures,” Design Automation for Embedded Systems, vol. 8, no. 2/3, pp. 189–210,
jun 2003.
M. Slijepcevic, C. Hernandez, J. Abella, and F. J. Cazorla, “Design and implementation of a fair credit-based bandwidth sharing scheme for buses,” in Proceedings of the 2017 Design, Automation and Test in Europe, DATE 2017. Institute of Electrical and Electronics Engineers Inc., may 2017, pp. 926–929.
F. E. Guibaly, “Design and Analysis of Arbitration Protocols,” IEEE Transactions on Computers, vol. 38, no. 2, pp. 161–171, 1989.
I. Ben-Hafaiedh, S. Graf, and M. Jaber, “Model-based design and distributed implementation of bus arbiter for multiprocessors,” in 2011 18th IEEE International Conference on Electronics, Circuits, and Systems, ICECS 2011, 2011, pp. 65–68.
A. M. and A. A., “A Bus Arbitration Scheme with an Efficient Utilization and Distribution,” International Journal of Advanced Computer Science and Applications, vol. 8, no. 3, 2017.
Y. Yang, R. Wu, L. Zhang, and D. Zhou, “An asynchronous adaptive priority round-robin arbiter based on four-phase dual-rail protocol,” Chinese Journal of Electronics, vol. 24, no. 1, pp. 1–7, jan 2015.
P. J. Bellardo, “CubeSat,” 2020. [Online]. Available: https://www.cubesat.org
M. Oveis-Gharan and G. N. Khan, “Index-based round-robin arbiter for NoC routers,” in Proceedings of IEEE Computer Society Annual Symposium on VLSI, ISVLSI, vol. 07-10-July. IEEE Computer Society, oct 2015, pp. 62–67.
K. Jain, S. K. Singh, A. Majumder, and A. J. Mondai, “Problems encountered in various arbitration techniques used in NOC router: A survey,” in 2015 International Conference on Electronic Design, Computer Networks and Automated Verification, EDCAV 2015. Institute of Electrical and Electronics Engineers Inc., mar 2015, pp. 62–67.
M. Pagani, E. Rossi, A. Biondi, M. Marinoni, G. Lipari, and G. Buttazzo, “A Bandwidth Reservation Mechanism for AXI-Based Hardware Accelerators on FPGAs,” in 31st Euromicro Conference on Real-Time Systems (ECRTS 2019), S. Quinton, Ed. Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik, 2019, pp. 24:1—-24:24.
M. Hernandez-Calvino, S. Ibarra-Delgado, R. Sandoval-Arechiga, J. Flores-Troncoso, and L. Garcia-Luciano, “Image Compressor IP-Core based on LOCO Algorithm for Space Photography Application,” in 2018 IEEE International Autumn Meeting on Power, Electronics and Computing (ROPEC). IEEE, nov 2018, pp. 1–4.
L. Garcia-Luciano, S. Ibarra-Delgado, H. Gallegos-Ruiz, and R. Sandoval-Arechiga, “Hardware implementation of a block cipher with AXI Stream Interface,” Memorias del Congreso Internacional de Investigaci´on Academia Journals Celaya 2017, vol. 9, no. 6, pp. 2245,2251, 2017.
W. J. Dally and B. P. Towles, Principles and practices of interconnection networks. Elsevier, 2004.
S. Q. Zheng and M. Yang, “Algorithm-hardware codesign of fast parallel round-robin arbiters,” IEEE Transactions on Parallel and Distributed Systems, vol. 18, no. 1, pp. 84–95, 2007.
Y.-L. Lee, J. M. Jou, and Y.-Y. Chen, “A high-speed and decentralized arbiter design for NoC,” in 2009 IEEE/ACS International Conference on Computer Systems and Applications. IEEE, may 2009, pp. 350–353.
K. Lahiri, A. Raghunathan, and G. Lakshminarayana, “The LOTTERYBUS on-chip communication architecture,” IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 14, no. 6, pp. 596–608, jun 2006.