Artigo submetido para a revista IEEE Latin America Transactions, no ano de 2023. Este trabalho investiga formas de representação de textos (e.g., word embeddings) que melhor discriminam textos musicais (letras). Os modelos foram avaliados na classificação de subgêneros musicais, problema cuja a superfície de separatividade entre as classes (de subgêneros) não é trival.
Fabrício A. do Carmo UEMA |
Jorge L. F. da Silva Junior UFOPA |
 Rafael G. Rossi iFood |
Fábio M. F. Lobato UFOPA | UEMA |
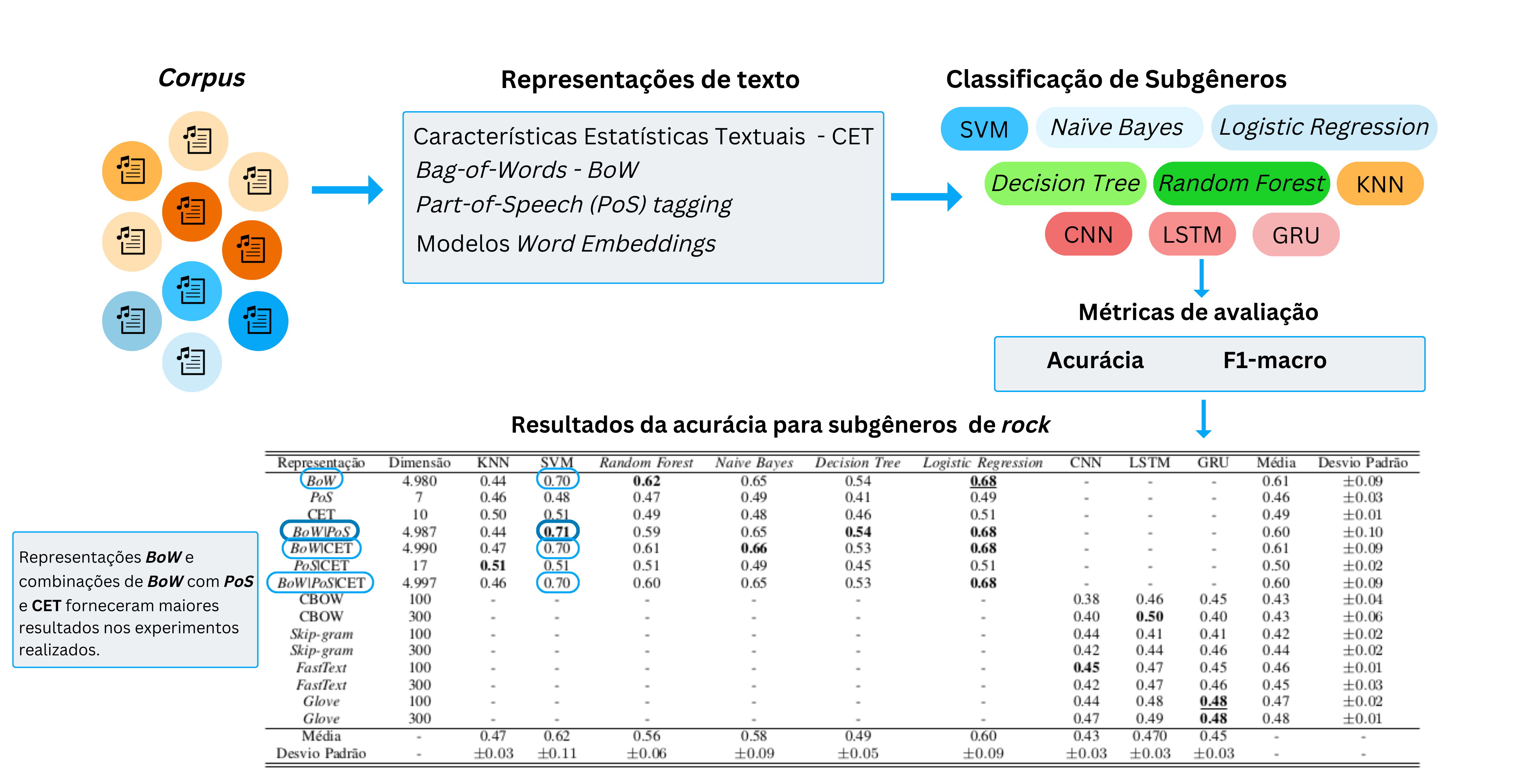
The advancement of techniques and computational tools for data mining has been boosting the music market with applications focused on user experience. These techniques explore musical data looking for patterns and trends that can guide business strategies. One of the key steps in these applications is the vector representation of the original text. This work approaches textual representation techniques applied to the problem of classifying musical sub-genres, an open topic in the field of musical information retrieval, whose complexity lies in the difficult identification of the separation boundary between the sub-classes of the same genre, since both carry several features in common. For this, experiments were carried out aiming at the best combination between classifier and textual representation models, using musical texts from rock and pop subgenres. The results showed that Bag-of-Words (BoW) and the SVM and Logistic Regression algorithms obtained better results compared to embeddings models and deep neural networks. The conclusions obtained have the potential to guide future studies for the classification of texts whose separability surfaces are subtle and challenging.